ElasticSearch
# 1.ES介绍
Elasticsearch是一个基于Lucene的搜索服务器、提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的
根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
# 2.ES可以做什么
- 信息检索
- 企业内部不系统搜索
- 关系型数据库使用like进行模糊检索,会导致索引失效,效率低下
- 可以基于Elasticsearch来进行检索,效率杠杠的
- 数据分析引擎
# 3.ES特点
- 海量数据处理
- 大型分布式集群(数百台规模服务器)
- 处理PB级数据
- 小公司也可以进行单机部署
- 开箱即用
- 简单易用,操作非常简单
- 快速部署生产环境
- 作为传统数据库的补充
- 传统关系型数据库不擅长全文检索(MySQL自带的全文索引,与ES性能差距非常大)
- 传统关系型数据库无法支持搜索排名、海量数据存储、分析等功能
- Elasticsearch可以作为传统关系数据库的补充,提供RDBM无法提供的功能
- 哪些公司在用
- 京东、携程、去哪儿、58同城、滴滴、今日头条、暴雪等
# 4.ES调优
# 设计阶段调优
- 根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索引;
- 使用别名进行索引管理
- 每天凌晨定时对索引做 force_merge 操作,以释放空间; 4、采取冷热分离机制,热数据存储到 SSD,提高检索效率;冷数据定期进行 shrink操作,以缩减存储;
- 采取 curator 进行索引的生命周期管理;
- 仅针对需要分词的字段,合理的设置分词器;
- Mapping 阶段充分结合各个字段的属性,是否需要检索、是否需要存储等。
# 写入调优
- 写入前副本数设置为 0;
- 写入前关闭 refresh_interval 设置为-1,禁用刷新机制;
- 写入过程中:采取 bulk 批量写入;
- 写入后恢复副本数和刷新间隔;
- 尽量使用自动生成的 id;
# 查询调优
禁用 wildcard;
禁用批量 terms(成百上千的场景);
充分利用倒排索引机制,能 keyword 类型尽量 keyword;
数据量大时候,可以先基于时间敲定索引再检索;
设置合理的路由机制
# 其他调优
- 部署调优,业务调优等
# 5.ES的倒排索引是什么
传统的我们的检索是通过文章,逐个遍历找到对应关键词的位置。
而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引。
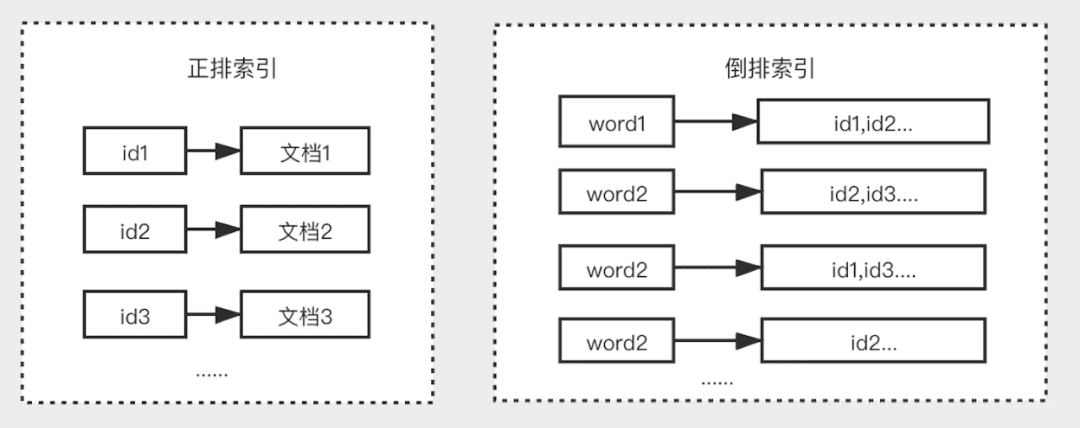
倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构
lucene 从 4+版本后开始大量使用的数据结构是 FST。FST 有两个优点:
空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
查询速度快。O(len(str))的查询时间复杂度。
# 6.倒排索引的生成过程
假设目前有以下两个文档内容:
苏州街维亚大厦
桔子酒店苏州街店
2
3
其处理步骤如下:
1、正排索引给每个文档进行编号,作为其唯一的标识。
| 文档 id | content |
|---|---|
| 1 | 苏州街维亚大厦 |
| 2 | 桔子酒店苏州街店 |
2、生成倒排索引:
- 首先要对字段的内容进行分词,分词就是将一段连续的文本按照语义拆分为多个单词,这里两个文档包含的关键词有:苏州街、维亚大厦…
- 然后按照单词来作为索引,对应的文档 id 建立一个链表,就能构成上述的倒排索引结构。
| Word | 文档 id |
|---|---|
| 苏州街 | 1,2 |
| 维亚大厦 | 1 |
| 维亚 | 1 |
| 桔子 | 2 |
| 酒店 | 2 |
| 大赛 | 1 |
有了倒排索引,能快速、灵活地实现各类搜索需求。整个搜索过程中我们不需要做任何文本的模糊匹配。
例如,如果需要在上述两个文档中查询 苏州街桔子 ,可以通过分词后 苏州街 查到 1、2,通过 桔子 查到 2,然后再进行取交取并等操作得到最终结果。

# 7.ES是如何实现 master 选举的
前置条件:
只有候选主节点(master:true)的节点才能成为主节点。
最小主节点数(min_master_nodes)的目的是防止脑裂。
实现步骤:
ElasticSearch的选举是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分
第一步:确认候选主节点数达标,就是我们在Es.yml 设置的值
第二步:比较:先判定是否具备 master 资格,具备候选主节点资格的优先返回;
若两节点都为候选主节点,则 id 小的值会主节点。注意这里的 id 为 string 类型。
补充:master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能。
# 8.ES对于大数据量(上亿量级)的聚合如何实现
Elasticsearch提供的首个近似聚合是cardinality度量。它提供一个字段的基数,即该字段的distinct或者unique值的数目。它是基于HLL算法的。HLL会先对我们的输入作哈希运算,然后根据哈希运算的结果中的bits做概率估算从而得到基数。其特点是:
支持配置精度,用来控制内存的使用(精度高=多内存);
小数据集精度非常高;
可以通过配置参数,来设置去重需要的固定内存使用量。
无论数千还是数十亿的唯一值,内存使用量只与ES配置的精确度相关。
# 9.解释一下ESNode
节点是Elasticsearch的实例。实际业务中,会说:ES集群包含3个节点、7个节点。
这里节点实际就是:一个独立的Elasticsearch进程,一般将一个节点部署到一台独立的服务器或者虚拟机、容器中。
不同节点根据角色不同,可以划分为:
主节点
- 帮助配置和管理在整个集群中添加和删除节点。
数据节点
- 存储数据并执行诸如CRUD(创建/读取/更新/删除)操作,对数据进行搜索和聚合的操作。
- 客户端节点(或者说:协调节点) 将集群请求转发到主节点,将与数据相关的请求转发到数据节点
- 摄取节点
用于在索引之前对文档进行预处理。
# 10.ES中分片是什么
Elasticsearch中的"分片"(Shard)是数据存储和搜索的基本单元。它们是用来水平分割数据的,以便在多个节点上分布数据和负载。分片在Elasticsearch中起到了关键的作用,使得Elasticsearch能够处理大量数据并提供高可用性。
以下是一些关于Elasticsearch分片的关键概念:
1.主分片(Primary Shard):每个索引都可以分成一个或多个主分片。主分片是数据的主要存储单元,它包含了索引的一部分数据。当你创建一个索引时,你可以指定主分片的数量。主分片是可读写的。
2.复制分片(Replica Shard):每个主分片都可以有零个或多个复制分片。复制分片是主分片的精确副本,用于提高数据的可用性和容错性。复制分片是只读的,并且可以分布在不同的节点上。复制分片的数量可以在索引创建或修改时指定。
3.分片策略(Sharding Strategy):Elasticsearch的分片策略允许数据被平均分布到集群中的不同节点上,以实现负载均衡和高可用性。这意味着查询可以并行执行,提高了性能。
4.故障转移(Failover):如果主分片因某种原因不可用(例如节点故障),复制分片将会被提升为新的主分片,确保数据的可用性。这种机制确保了数据的容错性。
5.查询优化:分片还有助于分布式查询的优化。Elasticsearch可以同时搜索多个分片,从而提高查询性能。
总之,Elasticsearch中的分片是数据的基本组成单元,它们允许你存储大量数据并实现高可用性、负载均衡和性能优化。理解如何管理分片对于有效使用Elasticsearch非常重要。当你创建索引时,你可以根据你的需求来设置主分片和复制分片的数量,以满足你的性能和可用性要求。
# 11.分片相关配置
1.主分片和副本分片数量的调整
将my-index索引的主分片数量调整为3,副本分片数量调整为2。
//PUT /my-index/_settings
{
"number_of_shards": 3,
"number_of_replicas": 2
}
2
3
4
5
2.新建索引时设置分片
将创建一个名为my-index的索引,主分片数量为3,副本分片数量为2。
//PUT /my-index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
2
3
4
5
6
7
3.添加索引分片
将从my-index索引中删除一个分片,并将其拆分到新的索引my-new-index中。新的索引主分片数量为2
//PUT /my-index/_shrink/my-new-index
{
"settings": {
"index.number_of_shards": 2
}
}
2
3
4
5
6
4.删除索引分片
将从my-index索引中删除一个主分片,并将其拆分到新的索引中。
//POST /my-index/_shrink
{
"settings": {
"index.routing.allocation.total_shards_per_node": 1,
"index.number_of_shards": 2
}
}
2
3
4
5
6
7
5.查看分片状态
显示my-index索引的每个分片的状态,包括主分片和副本分片。
GET /_cat/shards/my-index?v
# 12.分片的注意事项
1.过多的分片数量会影响性能
如果分片数量过多,将会对集群性能产生负面影响。每个分片都有一定的开销,包括Lucene和Elasticsearch本身的开销,过多的分片会增加这种开销,并产生其他额外的开销,如网络开销、磁盘IO等。
2.分片数量应与节点数量匹配
使用分片时,应考虑节点数量和可用资源情况,选择适当的分片数量。分片数量应与节点数量匹配,避免出现不均衡的情况。如果节点数量不足,可以通过添加新的节点来保持均衡的状态。
3.主副本分片应尽量分布在不同的节点上
为了防止节点故障造成数据丢失,副本分片应尽量分布在不同的节点上。这样可以保持数据的高可用性,并避免单点故障。
# 13.ES中的分析器是什么
分析(analysis)机制用于进行全文文本(Full Text)的分词,以建立供搜索用的反向索引。
1、在ElasticSearch中索引数据时,数据由为索引定义的Analyzer在内部进行转换。分析器由一个Tokenizer和零个或多个TokenFilter组成。
编译器可以在一个或多个CharFilter之前。分析模块允许您在逻辑名称下注册分析器,然后可以在映射定义或某些API中引用它们。
2、Elasticsearch附带了许多可以随时使用的预建分析器。或者可以组合内置的字符过滤器,编译器和过滤器器来创建自定义分析器。
# 14.ES中分析器由哪几部分组成
分析器由三部分构成:
字符过滤器(Character Filters)
分词器(Tokenizers)
分词过滤器(Token Filters)
一个分析器不一定这三个部分都有,但是一般会包含分词器。ES自带的分析器有如下几种:
Standard Analyzer、Simple Analyzer、Whitespace Analyzer、Stop Analyzer、Keyword Analyzer、Pattern Analyzer、Language Analyzers 和 Fingerprint Analyzer。
Elasticsearch内置了若干分析器类型,其中常用的是标准分析器,叫做”standard”。其中Standard Analyzer是ES默认的分析器,如果没有指定任何分析器的话,ES将默认使用这种分析器。
分析器(Analyzer)通常由一个Tokenizer(怎么分词),以及若干个TokenFilter(过滤分词)、Character Filter(过滤字符)组成。
# 15.在并发情况下,ES如果保证读写一致
可以通过版本号使用
乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
对于写操作
一致性级别支持 quorum/one/all,默认为 quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片会在一个不同的节点上重建。
对于读操作
可以设置replication 为 sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置 replication 为 async 时,也可以通过设置搜索请求参数_preference 为 primary 来查询主分片,确保文档是最新版本。
# 16.ES有关的主要可用字段数据类型
字符串数据类型
全文检索的 text 类型、精准匹配的 keyword 类型
数值数据类型
字节,短整数,长整数,浮点数,双精度数,half_float,scaled_float
日期类型
日期纳秒Date nanoseconds,布尔值,二进制(Base64编码的字符串)
范围
整数范围 integer_range,长范围 long_range,双精度范围 double_range,浮动范围float_range,日期范围 date_range
包含对象的复杂数据类型
nested 、Object
GEO 地理位置相关类型
特定类型
数组(数组中的值应具有相同的数据类型)
# 17.ES中的集群、节点、索引、文档、类型是什么
群集:一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。群集由唯一名称标识,默认情况下为“elasticsearch”。此名称很重要,因为如果节点设置为按名称加入群集,则该节点只能是群集的一部分。
节点:属于集群一部分的单个服务器。它存储数据并参与群集索引和搜索功能。
索引:就像关系数据库中的“数据库”。它有一个定义多种类型的映射。索引是逻辑名称空间,映射到一个或多个主分片,并且可以有零个或多个副本分片。(eg: MySQL =>数据库 ElasticSearch =>索引)
文档:类似于关系数据库中的一行。不同之处在于索引中的每个文档可以具有不同的结构(字段),但是对于通用字段应该具有相同的数据类型。
MySQL => Databases => Tables => Columns / Rows ElasticSearch => Indices => Types =>具有属性的文档
类型:是索引的逻辑类别/分区,其语义完全取决于用户。
# 18.详细描述一下ES索引文档的过程
这里的索引文档应该理解为文档写入 ES,创建索引的过程。
文档写入包含:单文档写入和批量 bulk 写入,这里只解释一下:单文档写入流程。
记住官方文档中的这个图。

**第一步:**客户写集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演路由节点的角色。)
**第二步:**节点 1 接受到请求后,使用文档_id 来确定文档属于分片 0。请求会被转到另外的节点,假定节点 3。因此分片 0 的主分片分配到节点 3 上。
**第三步:**节点 3 在主分片上执行写操作,如果成功,则将请求并行转发到节点 1和节点 2 的副本分片上,等待结果返回。所有的副本分片都报告成功,节点 3 将向协调节点(节点 1)报告成功,节点 1 向请求客户端报告写入成功。
如果面试官再问:第二步中的文档获取分片的过程?
回答:借助路由算法获取,路由算法就是根据路由和文档 id 计算目标的分片 id 的
过程。
1shard = hash(_routing) % (num_of_primary_shards)
# 19.详细描述一下ES搜索的过程
搜索拆解为“query then fetch” 两个阶段。
query 阶段的目的:定位到位置,但不取
步骤拆解如下:
假设一个索引数据有 5 主+1 副本 共 10 分片,一次请求会命中(主或者副本分片中)的一个。
每个分片在本地进行查询,结果返回到本地有序的优先队列中。
第 2)步骤的结果发送到协调节点,协调节点产生一个全局的排序列表。
fetch 阶段的目的:取数据。
- 路由节点获取所有文档,返回给客户端
# 20.ES在部署时,对Linux的设置有哪些优化方法
1、关闭缓存 swap;
2、堆内存设置为:Min(节点内存/2, 32GB);
3、设置最大文件句柄数;
4、线程池+队列大小根据业务需要做调整;
5、磁盘存储 raid 方式——存储有条件使用 RAID10,增加单节点性能以及避免单节点存储故障。
# 21.详细描述一下ES更新和删除文档的过程
1、删除和更新也都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更;
2、磁盘上的每个段都有一个相应的.del 文件。当删除请求发送后,文档并没有真的被删除,而是在.del 文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del 文件中被标记为删除的文档将不会被写入新段。
3、在新的文档被创建时,Elasticsearch 会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del 文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
# 22.是否了解字典树
常用字典数据结构如下所示

Trie 的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
3 个基本性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符。
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
每个节点的所有子节点包含的字符都不相同。

1、可以看到,trie 树每一层的节点数是 26^i 级别的。所以为了节省空间,我们
还可以用动态链表,或者用数组来模拟动态。而空间的花费,不会超过单词数×单
词长度。
2、实现:对每个结点开一个字母集大小的数组,每个结点挂一个链表,使用左儿
子右兄弟表示法记录这棵树;
3、对于中文的字典树,每个节点的子节点用一个哈希表存储,这样就不用浪费太
大的空间,而且查询速度上可以保留哈希的复杂度 O(1)。
用途:
字典树可以被广泛应用于字符串检索和匹配问题
- 实现字符串自动补全和纠错功能。
- 在搜索引擎中实现关键词提示。
- 统计和查找文本中的特定单词或短语出现的次数。
- 在数据压缩领域中,实现基于前缀编码的数据压缩。
实现:
树结构
//其中 count 表示以当前单词结尾的单词数量。prefix 表示以该处节点之前的字符串为前缀的单词数量
public class TrieNode {
int count;
int prefix;
TrieNode[] nextNode=new TrieNode[26];
public TrieNode(){
count=0;
prefix=0;
}
}
2
3
4
5
6
7
8
9
10
创建树
//插入一个新单词
public static void insert(TrieNode root,String str){
if(root==null||str.length()==0){
return;
}
char[] c=str.toCharArray();
for(int i=0;i<str.length();i++){
//如果该分支不存在,创建一个新节点
if(root.nextNode[c[i]-'a']==null){
root.nextNode[c[i]-'a']=new TrieNode();
}
root=root.nextNode[c[i]-'a'];
root.prefix++;//注意,应该加在后面
}
//以该节点结尾的单词数+1
root.count++;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
查询单词或前缀的数量
//查找该单词是否存在,如果存在返回数量,不存在返回-1
public static int search(TrieNode root,String str){
if(root==null||str.length()==0){
return -1;
}
char[] c=str.toCharArray();
for(int i=0;i<str.length();i++){
//如果该分支不存在,表名该单词不存在
if(root.nextNode[c[i]-'a']==null){
return -1;
}
//如果存在,则继续向下遍历
root=root.nextNode[c[i]-'a'];
}
//如果count==0,也说明该单词不存在
if(root.count==0){
return -1;
}
return root.count;
}
//查询以str为前缀的单词数量
public static int searchPrefix(TrieNode root,String str){
if(root==null||str.length()==0){
return -1;
}
char[] c=str.toCharArray();
for(int i=0;i<str.length();i++){
//如果该分支不存在,表名该单词不存在
if(root.nextNode[c[i]-'a']==null){
return -1;
}
//如果存在,则继续向下遍历
root=root.nextNode[c[i]-'a'];
}
return root.prefix;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
测试
class Main {
public static void main(String[] args) {
TrieNode newNode=new TrieNode();
TrieNode.insert(newNode,"hello");
TrieNode.insert(newNode,"hello");
TrieNode.insert(newNode,"hello");
TrieNode.insert(newNode,"helloworld");
System.out.println(TrieNode.search(newNode,"hello"));
System.out.println(TrieNode.searchPrefix(newNode,"he"));
}
}
2
3
4
5
6
7
8
9
10
11
运行输出:
3
4
2
# 23.ES更新数据的执行流程
- 将原来的doc标识为deleted状态,然后新写入一条数据。
- buffer每refresh一次,就会产生一个segmentfile,所以默认情况下是1s一个segmentfile,segmentfile会越来越多,此时会定期执行merge。
- 每次merge时,会将多个segmentfile合并成一个,同时这里会将标识为deleted的doc给物理删除掉,然后将新的segmentfile写入磁盘,这里会写一个commitpoint,标识所有新的segmentfile,然后打开segmentfile供搜索使用,同时删除旧的segmentfile