文档查询之RequestBodySearch
# 1.入参介绍
# 1.1 Query DSL
ElasticSearch 搜索形式Request Body Search的入参使用的是查询表达式(Query DSL)。
查询表达式(
Query DSL)是一种非常灵活又富有表现力的查询语言。Elasticsearch使用它可以以简单的JSON接口来展现Lucene功能的绝大部分。在你的应用中,你应该用它来编写你的查询语句。它可以使你的查询语句更灵活、更精确、易读和易调试。
# 1.2 语法结构
{
"query": {},//查询条件
"sort": [ // 根据字段排序
{
"FIELD": {
"order": "desc"
}
}
],
"from": 0,//从第几条开始取
"size": 20,//取几条数据
"timeout": "1s", //设置超时时间
"_source": "{field}"//指定返回的字段
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 2.全文搜索
针对text类型的字段进行全文检索,会对查询语句先进行分词处理,如 match,match_phrase 等 query 类型。
# 2.1 match
# 1.常规使用
# 查询home中有`京`的记录
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match": {
"home": "京"
}
}
}'
2
3
4
5
6
7
8
# 2.参数: operator
operator`:查询条件的关系,值:`and(并且)、or(或者)`,默认是:`or
# 查询home中有`2`和`13`的记录 (并且)
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match": {
"home": {
"query": "2 13",
"operator": "and"
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
需要注意的是,如果字段类型是
keyword,则需要精准匹配,如姓名:张三,需要搜索张三,
# 3.参数: lenient
表示用来在查询时如果数据类型不匹配且无法转换时会报错。如果设置成 true 会忽略错误,默认是:false。
不设置时,报错:
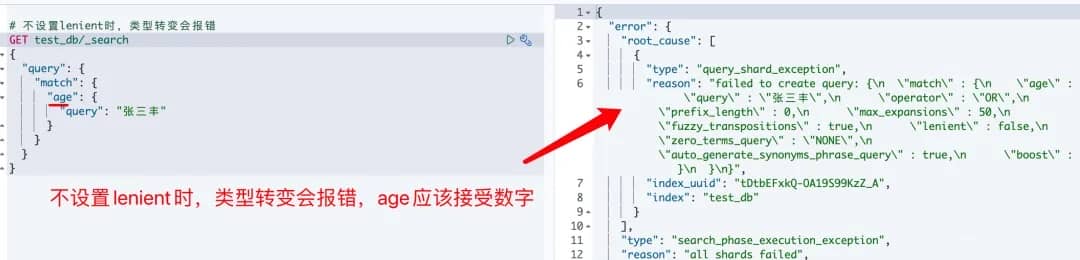
设置时,不报错:
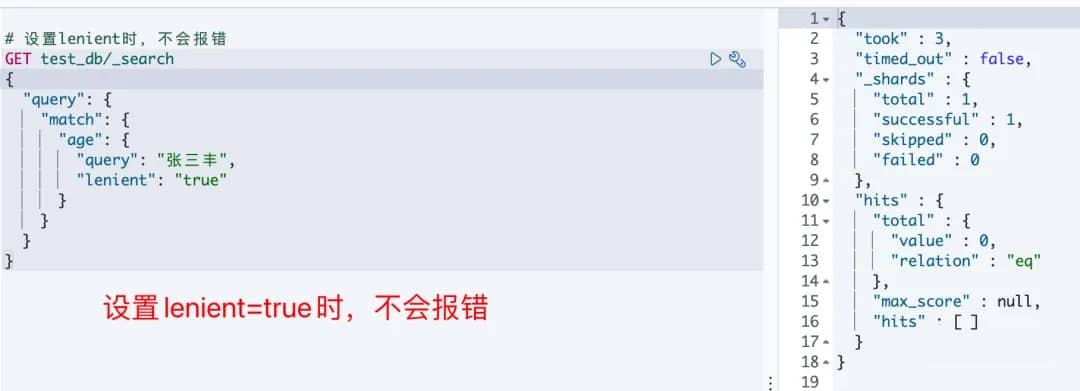
# 对应命令行请求
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match": {
"age": {
"query": "张三丰",
"lenient": "true"
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
# 4.参数:fuzziness
fuzziness :可以查询字段具有模糊搜索的特性,那什么是模糊搜索呢?
模糊搜索是指系统允许被搜索信息和搜索提问之间存在一定的差异,这种差异就是“模糊”在搜索中的含义。例如,查找名字
Smith时,就会找出与之相似的Smithe, Smythe, Smyth, Smitt等。——百度百科
参数取值说明:
在查询 text 或者 keyword 类型的字段时, fuzziness 可以看做是莱文斯坦距离。
fuzziness 参数的取值如下
0,1,2: 表示最大可允许的莱文斯坦距离AUTO:会根据词项的长度来产生可编辑距离,它还有两个可选参数,形式为AUTO:[low],[high], 分别表示短距离参数和长距离参数;如果没有指定,默认值是AUTO:3,6。
fuzziness在绝大多数场合都应该设置成AUTO
使用示例:
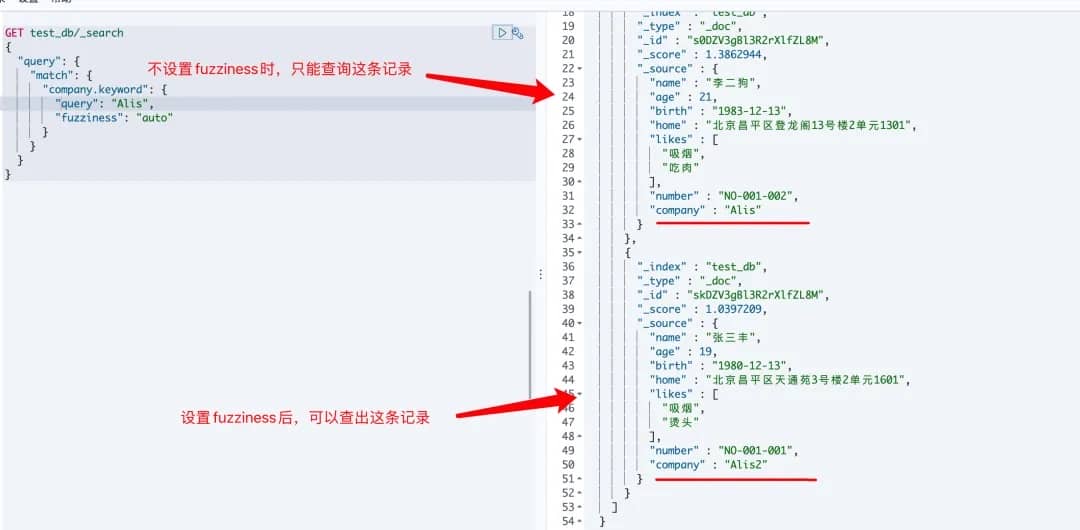
# 对应命令行请求
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match": {
"company.keyword": {
"query": "Alis",
"fuzziness": "auto"
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
# 2.2 match_all
查询简单的匹配所有文档。在没有指定查询方式时,它是默认的查询:
# 查询所有记录
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match_all": {}
}
}'
2
3
4
5
6
# 2.3 match_phrase
类似 match 查询, match_phrase 查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索,但只保留那些包含 全部 搜索词项,且 位置 与搜索词项相同的文档。比如对于 quick fox 的短语搜索可能不会匹配到任何文档,因为没有文档包含的 quick 词之后紧跟着 fox 。
使用示例:
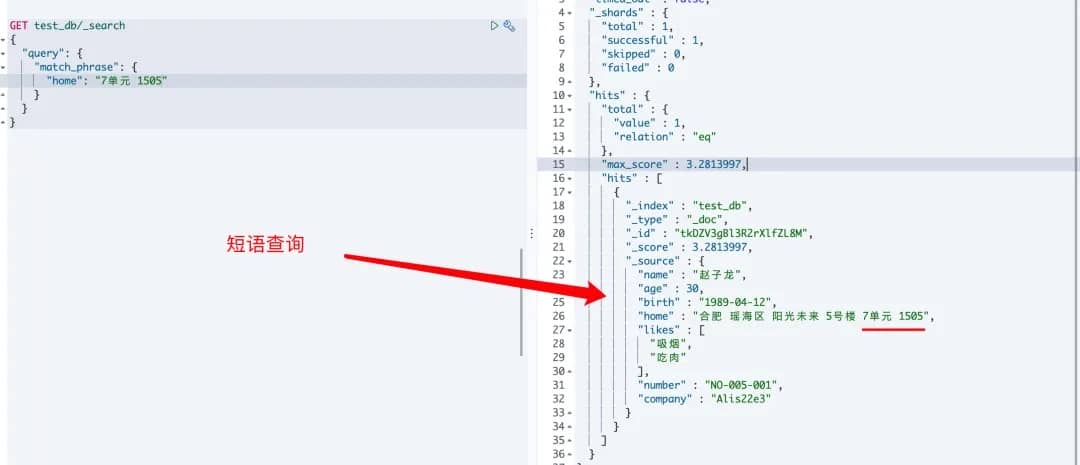
# 对应命令行请求
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match_phrase": {
"home": "7单元 1505"
}
}
}'
2
3
4
5
6
7
8
# 2.4 混合使用
精确短语匹配 或许是过于严格了。也许我们想要包含 quick brown fox 的文档也能够匹配 quick fox , 尽管情形不完全相同。
我们能够通过使用
slop参数将灵活度引入短语匹配中
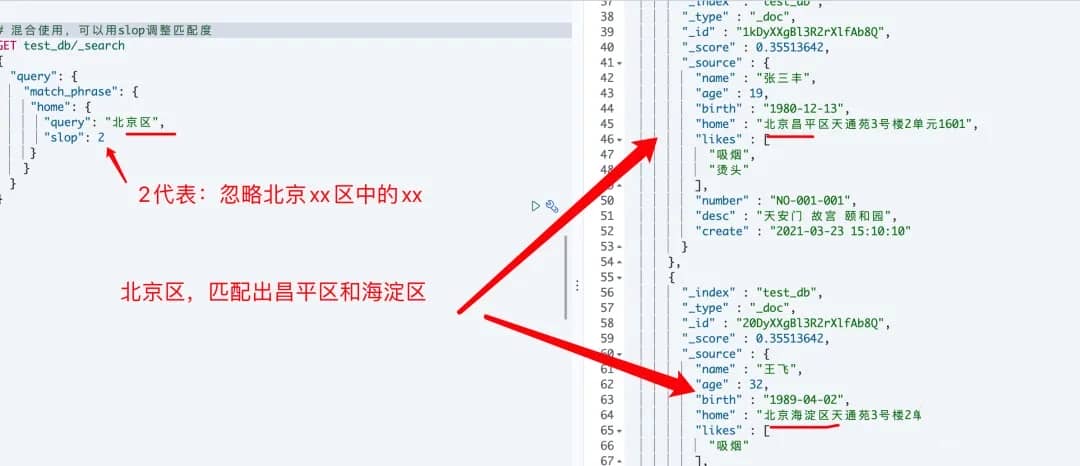
# 对应命令行请求
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match_phrase": {
"home": {
"query": "北京区",
"slop": 2
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
# 3.结构化搜索
# 3.1 精确查找(term和terms)
# 1. term (评分模式)
注意: 示例中的
name类型为keyword
# where name ='赵子龙'
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query":{
"term":{
"name":"赵子龙"
}
}
}'
2
3
4
5
6
7
8
精准查找只能适用一些不会被分词的字段类型比如:keyword。
# 2. term (非评分模式)
在
constant_score查询中,它可以包含查询或过滤,为任意一个匹配的文档指定评分1,忽略 TF/IDF 信息。
# where name ='赵子龙'
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "赵子龙"
}
},
"boost": 1.2 # 指定评分值
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
# 3. terms (搜索多字段)
# where name ='赵子龙' or name ='张三丰'
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"terms": {
"name": [
"赵子龙",
"张三丰"
]
}
}
}'
2
3
4
5
6
7
8
9
10
11
# 3.2 组合查询
# 1.查询结构
{
"query": {
"bool": {
"must": [
{}
],
"must_not": [
{}
],
"should": [
{}
],
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 2.过滤器
| 过滤词 | 描述 |
|---|---|
must | 所有的语句都 必须(must) 匹配,与 AND 等价。 |
must_not | 所有的语句都 不能(must not) 匹配,与 NOT 等价。 |
should | 至少有一个语句要匹配,与 OR 等价。 |
# 3.常规使用
# 查找`home`中包含`北京`,并且`likes`中没有`烫头`的记录
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query":{
"bool":{
"must":[
{ "match_phrase":{"home":"北京"}}
],
"must_not":[
{ "match":{"likes":"烫头"}}
]
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
# 4.结合filter
# where home like '%北京%' and name='王飞'
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"bool": {
"must": [
{"match": {"home": "北京"}}
],
"filter": {
"term": {
"name": "王飞"
}
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 5.提高Should精确度
所有 must 语句必须匹配,所有 must_not 语句都必须不匹配,但有多少 should 语句应该匹配呢?默认情况下,没有 should 语句是必须匹配的,只有一个例外:那就是当没有 must 语句的时候,至少有一个 should 语句必须匹配。
我们可以通过
minimum_should_match参数控制需要匹配的should语句的数量,它既可以是一个绝对的数字,又可以是个百分比
# 至少满足两个条件
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"bool": {
"should": [
{ "match": {"home": "单元"}},
{ "match": {"likes": "吃肉"}},
{ "match": {"desc": "老男孩"}}
],
"minimum_should_match": 2
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
# 6.提高查询优先级
每条查询语句贡献评分概率是一致时,可能并不是我们想要的。我们通过 boost 参数,来提高具体查询语句的优先级,如下示例
# 提高字段match_phrase查询条件的优先级
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"home": {
"query": "北京",
"boost":2.0
}
}
},
{
"match": {
"desc": "男孩"
}
}
]
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 3.3 范围查询
| 比较词 | 描述 |
|---|---|
| gt | > 大于 |
lt | < 小于 |
gte | >= 大于或等于 |
lte | <= 小于或等于 |
# 1.数字范围
# where age >= 10 and age <= 20
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
# 2.日期范围
# 查找 生日范围在 1990-01-01 < birth < 1998-01-01 之间的记录
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"range": {
"birth": {
"gt": "1990-01-01",
"lt": "1998-01-01"
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
# 3.时间计算
# 查询 指定时间减去1小时 ~ 指定时间
# 这里查询的是 2021-03-23 14:00:00 < 2021-03-23 15:00:00 的记录
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"range": {
"create": {
"gt": "2021-03-23 15:00:00||-1h"
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
# 3.4 过滤查询
# 1.(exists)查询存在
# 查询存在 name 字段的结果
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"exists": {
"field":"name"
}
}
}'
2
3
4
5
6
7
8
# 4.多字段搜索
# 4.1 使用 bool
# 查找字段`home`包含`北京` 或者 字段`likes`包含`吃肉`的记录
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"bool": {
"should": [
{ "match_phrase": {"home": "北京"}},
{ "match": {"likes": "吃肉"}}
]
}
}
}'
2
3
4
5
6
7
8
9
10
11
# 4.2使用 multi_match
# 1.查询结构
{
"query": {
"multi_match": {
"query": "",
"type":"",
"fields": [],
"operator":"and/or",
"tie_breaker":0,
"minimum_should_match":1
}
}
}
2
3
4
5
6
7
8
9
10
11
12
| 参数 | 描述 |
|---|---|
query | 查询值 |
fields | 指定查询字段 |
operator | 描述字段间关系,是同时并且还是或;值为:and、or |
tie_breaker | 评分系数(在现有得分基础上乘以系数);值推荐范围 0-1直接 |
minimum_should_match | 控制满足条件比例,可以是一个数字,也可以是个百分比 |
type | best_fileds: 默认打分方式,取最高的分数作为文档的分数,与dis_max相同。 most_fileds: 所有文档字段得分相加。 cross_fileds: 以分词为单位计算总分; 搜索词在不同的fields中的最大值作为这个词的打分,然后将每个词的打分相加。 |
# 2.使用
# 在字段"home","desc"搜索包含`天`的记录
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"multi_match": {
"query": "天",
"fields": ["home","desc"],
"operator": "and",
"tie_breaker": 0.3,
"minimum_should_match": 1
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
# 3.查询字段模糊匹配
字段名称可以用模糊匹配的方式给出:任何与模糊模式正则匹配的字段都会被包括在搜索条件中,例如可以使用以下方式同时匹配 book_title 、 chapter_title 和 section_title (书名、章名、节名)这三个字段:
{
"query": {
"multi_match": {
"query": "天",
"fields": ["*_title"]
}
}
}
2
3
4
5
6
7
8
# 4.提供单字段权重
可以使用 ^ 字符语法为单个字段提升权重,在字段名称的末尾添加 ^boost ,其中 boost 是一个浮点数:
{
"query": {
"multi_match": {
"query": "天",
"fields": ["home","desc^2"] #desc字段提高了权重
}
}
}
2
3
4
5
6
7
8
# 5.部分搜索
# 5.1 前缀查询
下面例子中,字段name的类型是keyword,通过前缀也能查询结果。
#虽然name类型是keyword,通过前缀一样可以搜出:名字带李的
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"prefix": {
"name": {
"value": "李"
}
}
}
}'
2
3
4
5
6
7
8
9
10
# 5.2 通配符和正则表达式
与 prefix 前缀查询的特性类似, wildcard 通配符查询也是一种底层基于词的查询,与前缀查询不同的是它允许指定匹配的正则式。它使用标准的 shell 通配符查询:? 匹配任意字符, * 匹配 0 或多个字符。
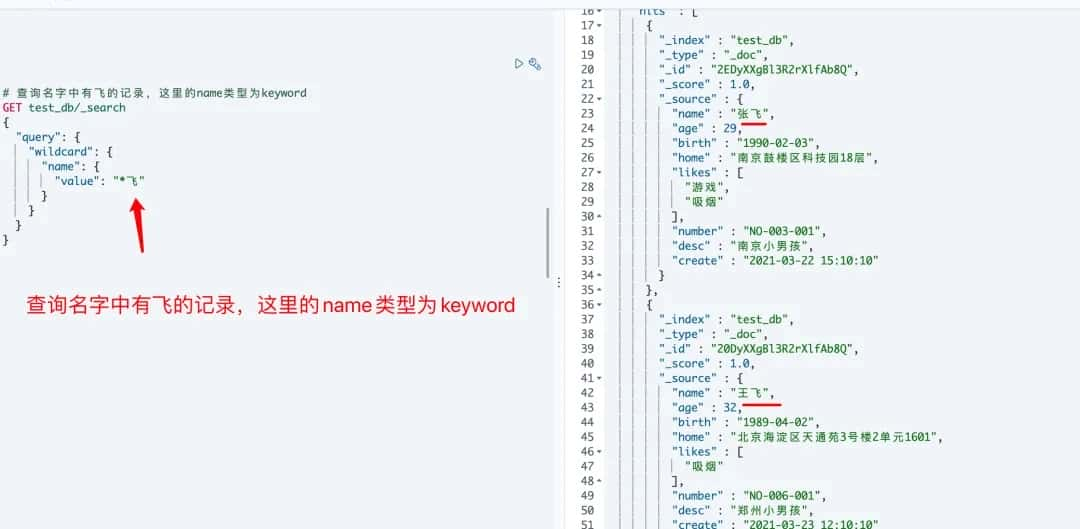
# 对应命令行请求
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"wildcard": {
"name": {
"value": "*飞"
}
}
}
}'
2
3
4
5
6
7
8
9
10
@注意事项:
prefix、wildcard和regexp查询是基于词操作的,如果用它们来查询analyzed字段,它们会检查字段里面的每个词,而不是将字段作为整体来处理。比方说包含 “Quick brown fox” (快速的棕色狐狸)的
title字段会生成词:quick、brown和fox。会匹配
{ "regexp": { "title": "br.*" }}1但是不会匹配
{ "regexp": { "title": "Qu.*" }} { "regexp": { "title": "quick br*" }}1
2
# 5.3 即时搜索
用户已经渐渐习惯在输完查询内容之前,就能为他们展现搜索结果,这就是所谓的 即时搜索(instant search) 或 输入即搜索(search-as-you-type) 。不仅用户能在更短的时间内得到搜索结果,我们也能引导用户搜索索引中真实存在的结果。
对于查询时的输入即搜索,可以使用 match_phrase 的一种特殊形式, match_phrase_prefix 查询。
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match_phrase_prefix": {
"home": "北京"
}
}
}'
2
3
4
5
6
7
# 6.分页搜索
ElasticSearch提供了3种方式来解决分页与遍历的问题,分别是以下三种。
# 6.1 from/size
from:指明开始位置; size:指明获取总数
# 从0开始,每页获取2条
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}'
2
3
4
5
6
7
8
# 6.2 scoll (游标查询)
scroll 查询 可以用来对 Elasticsearch 有效地执行大批量的文档查询,而又不用付出深度分页那种代价。
游标查询会取某个时间点的快照数据。查询初始化之后索引上的任何变化会被它忽略。它通过保存旧的数据文件来实现这个特性,结果就像保留初始化时的索引 视图 一样。
深度分页的代价根源是结果集全局排序,如果去掉全局排序的特性的话查询结果的成本就会很低。游标查询用字段
_doc来排序。这个指令让 Elasticsearch 仅仅从还有结果的分片返回下一批结果。
# 1.调用流程
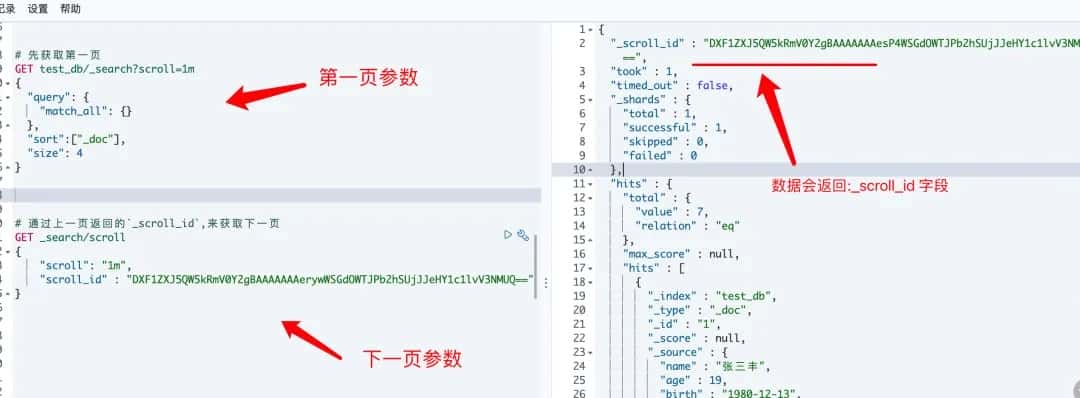
# 第一页,每页取4条
curl -XGET "http://elasticsearch:9200/test_db/_search?scroll=1m" -H 'Content-Type: application/json' -d'{
"query": {
"match_all": {}
},
"sort":["_doc"],
"size": 4
}'
# 下一页
curl -XGET "http://elasticsearch:9200/_search/scroll" -H 'Content-Type: application/json' -d'{
"scroll": "1m",
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAerywWSGdOWTJPb2hSUjJJeHY1c1lvV3NMUQ=="
}'
2
3
4
5
6
7
8
9
10
11
12
13
scroll=1m:设置游标查询的过期时间为1m,过期时间会在每次做查询的时候刷新,所以这个时间只需要足够处理当前批的结果就可以了,而不是处理查询结果的所有文档的所需时间。这个过期时间的参数很重要,因为保持这个游标查询窗口需要消耗资源,所以我们期望如果不再需要维护这种资源就该早点儿释放掉。设置这个超时能够让 Elasticsearch 在稍后空闲的时候自动释放这部分资源。
# 6.3 search_after
为了避免深度分页,可以实时获取下一页的文档信息,但是有以下限制需要注意:
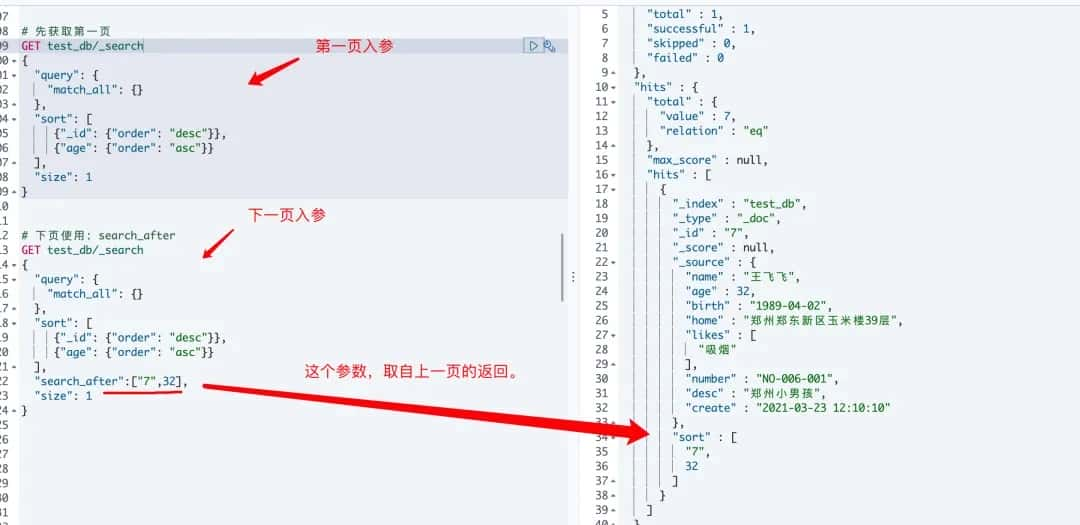
# 第一页
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match_all": {}
},
"sort": [
{"_id": {"order": "desc"}},
{"age": {"order": "asc"}}
],
"size": 1
}'
# 下一页
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match_all": {}
},
"sort": [
{"_id": {"order": "desc"}},
{"age": {"order": "asc"}}
],
"search_after":["7",32],
"size": 1
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
search_after:里面值的数量,必须和sort参与排序字段数量一致。
# 6.4 三种分页使用场景
| 分页方式 | 使用场景 |
|---|---|
from/size | 需要实时获取顶部的部分文档,且需要自由翻页 |
scroll | 需要全部文档,如导出所有数据的功能 |
search_after | 需要全部文档,不需要自由翻页 |
# 7.高亮搜索
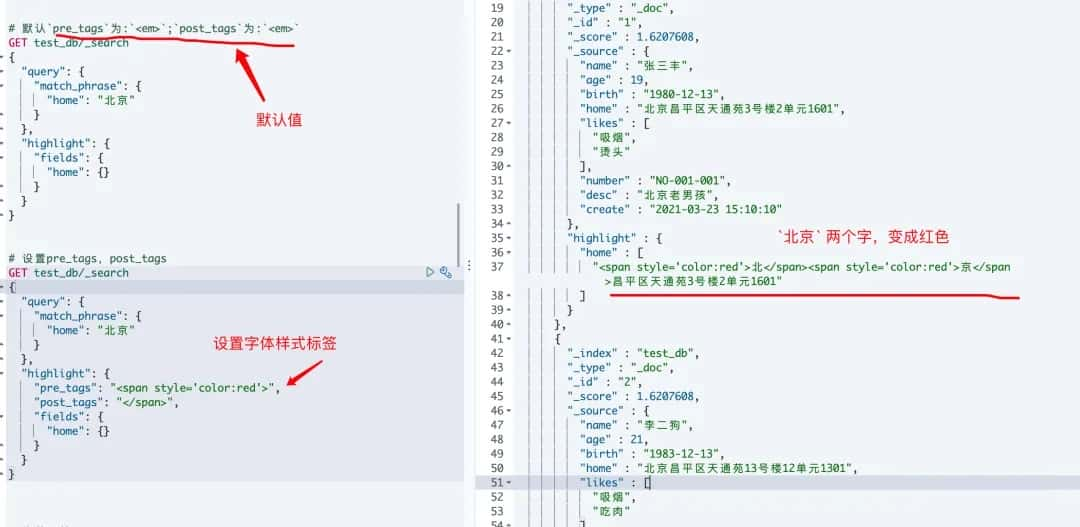
# 对应命令行请求
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match_phrase": {
"home": "北京"
}
},
"highlight": {
"pre_tags": "<span style=\"color:red\">",
"post_tags": "</span>",
"fields": {
"home": {}
}
}
}'
# 也可以传 class样式
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"query": {
"match_phrase": {
"home": "北京"
}
},
"highlight": {
"pre_tags": "<span class=\"red\">",
"post_tags": "</span>",
"fields": {
"home": {}
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31