聚合查询
Salted Fish 1991/6/26 基础
# 1.什么是聚合分析
聚合分析是值ElasticSearch除搜索功能外提供的针对ElasticSearch数据做统计分析的功能
- 功能丰富:提供
Bucket,Metric,Pipeline等多种分析方式,可以满足大部分的分析需求 - 实时性高:所有的计算结果都是及时返回的,而
Hadoop等大数据系统一般都是T+1的。
# 2.聚合分类
| 名称 | 作用 | 对比Mysql |
|---|---|---|
分桶类型 (Bucket) | 满足特定条件的文档的集合 | 类似GROUP BY语法 |
指标分析类型(Metric) | 计算最大值,最小值,平均值等 | 类似 COUNT 、 SUM() 、 MAX() 等统计方法 |
管道分析类型(Pipeline) | 对聚合结果进行二次分析 | |
矩阵分析类型(Matrix) | 支持对多个字段的操作并提供一个结果矩阵 |
# 3.Bucket聚合分析
按照Bucket的分桶策略,常见的Bucket聚合分析如下:
| 策略 | 描述 |
|---|---|
Terms | 最简单策略,如果是text类型,则按照分词后的结果分桶 |
Range | 按照指定数值的范围来设定分桶规则 |
Date Range | 通过指定日期的范围来设定分桶规则 |
Histogram | 直方图,以固定间隔的策略来分割数据 |
Date Histogram | 针对日期的直方图或者柱状图,是时序数据分析中常用的聚合分析类型 |
# 3.1 Terms
最简单策略,如果是text类型,则按照分词后的结果分桶
# 1.语法
{
"size":0,//hits返回的数量,默认20条
"aggs": {
"可自定义分组名": {
"terms": {
"field": "指定字段",
"size": 3// 查询的数量
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 2.使用
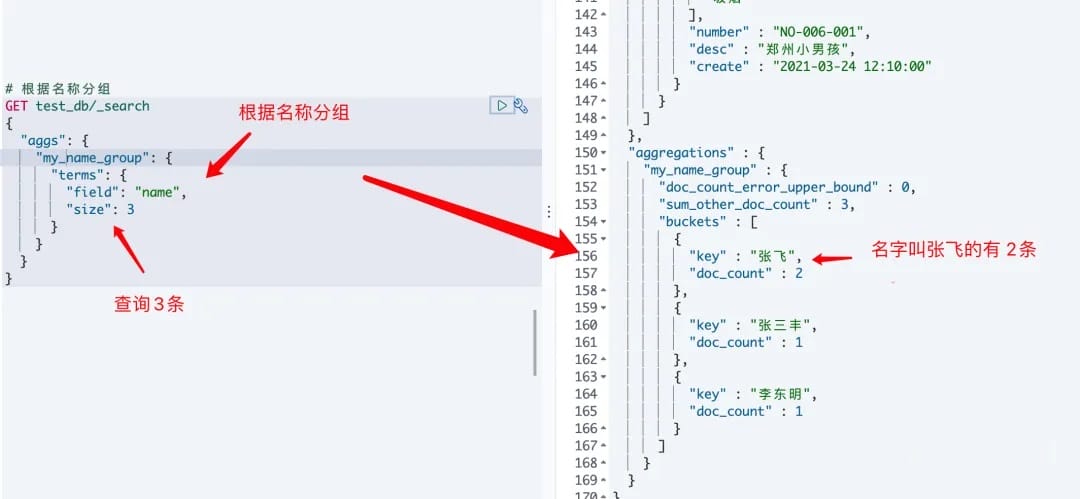
# 根据名称分组
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"aggs": {
"my_name_group": {
"terms": {
"field": "name",
"size": 3
}
}
}
}'
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 3.2 Range
按照指定数值的范围来设定分桶规则
# 1.语法
{
"size":0,//hits返回的数量,默认20条
"aggs": {
"可自定义分组名": {
"range": {
"field": "字段",
"ranges": [
{
"from": 10, // 大于等于
"to": 20 // 小于
},
{
"from": 20, // 大于等于
"to": 30 // 小于
},
...
]
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 2.使用
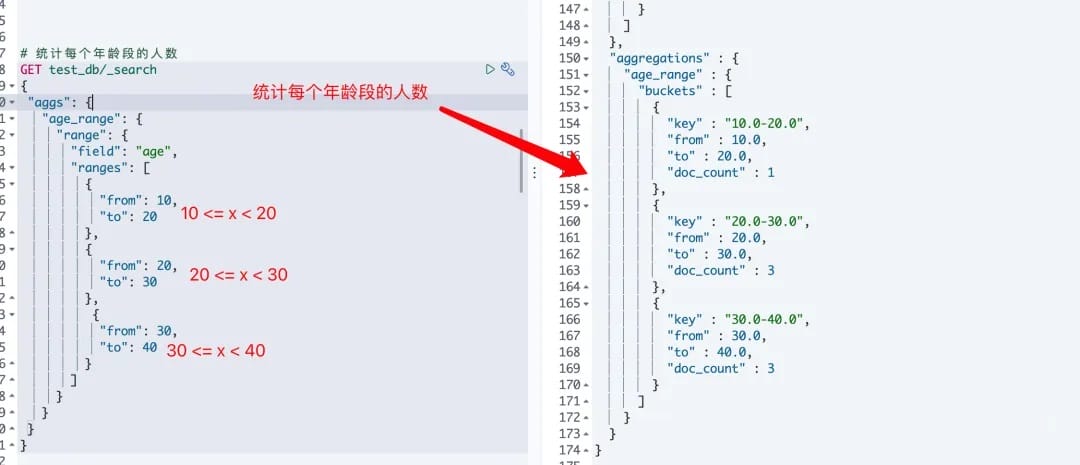
#统计年龄分布在 20 <= x < 30 的人数
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"aggs": {
"age_range": {
"range": {
"field": "age",
"ranges": [
{
"from": 10,
"to": 20
},
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
}
]
}
}
}
}'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 3.3 Date Range
通过指定日期的范围来设定分桶规则
# 1.语法
{
"size":0,//hits返回的数量,默认20条
"aggs": {
"可自定义分组名": {
"date_range": {
"field": "字段",
"ranges": [
{
"from": "begin", //格式为:yyyy-MM-dd HH:mm:ss
"to": "end" // 格式为:yyyy-MM-dd HH:mm:ss
},
{
"from": "now-10d/d", //当前时间减去10天,格式为:yyyy-MM-dd HH:mm:ss
"to": "now" // 当前时间,格式为:yyyy-MM-dd HH:mm:ss
}
]
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 2.使用
# 3.4 Histogram
直方图,以固定间隔的策略来分割数据
# 1.语法
{
"size": 0, //hits返回的数量,默认20条
"aggs": {
"NAME": {
"histogram": {
"field": "字段",
"interval": 10, // 步长
"extended_bounds": {
"min": 10,// 最小值 x >= 10
"max": 40 // 最大值 x <= 40
}
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 2.使用
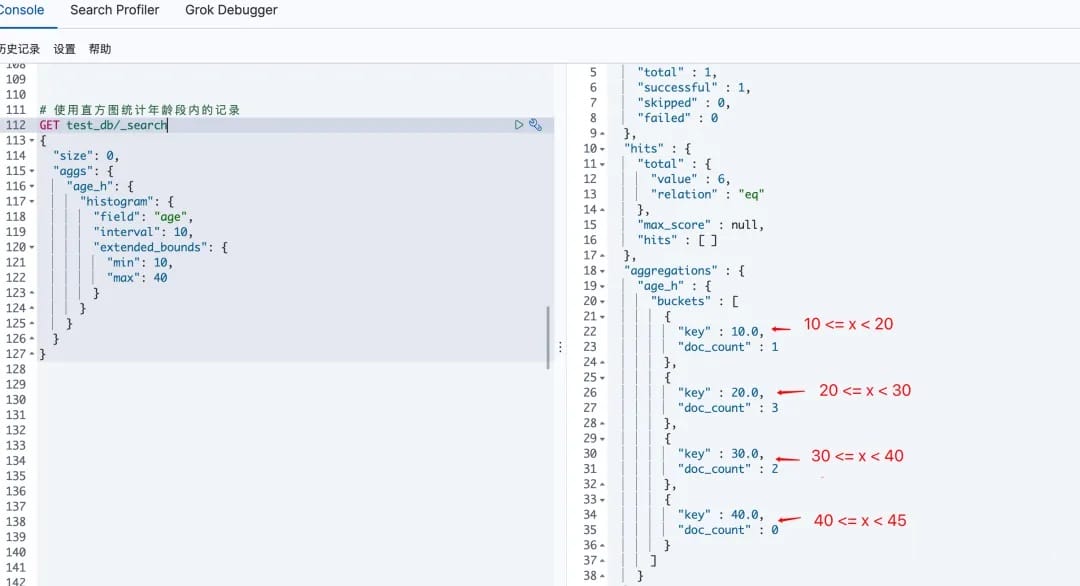
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"size": 0,
"aggs": {
"NAME": {
"histogram": {
"field": "age",
"interval": 10,
"extended_bounds": {
"min": 10,
"max": 40
}
}
}
}
}'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 3.5 Date Histogram
针对日期的直方图或者柱状图,是时序数据分析中常用的聚合分析类型
# 1.语法
{
"size": 0,
"aggs": {
"NAME": {
"date_histogram": {
"field": "字段",
"interval": "day",// 维度
"format": "yyyy-MM-dd",//格式化日期
"extended_bounds": {
"min": "最小值",
"max": "最大值"
}
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
interval`:值有:`year、month、week、day、hour、minute1
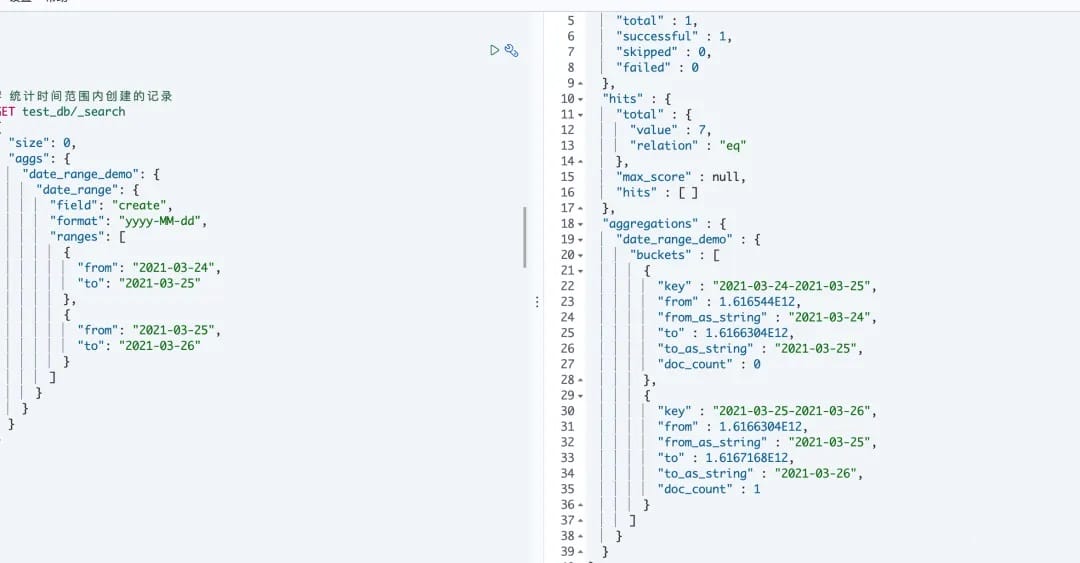
# 2.使用
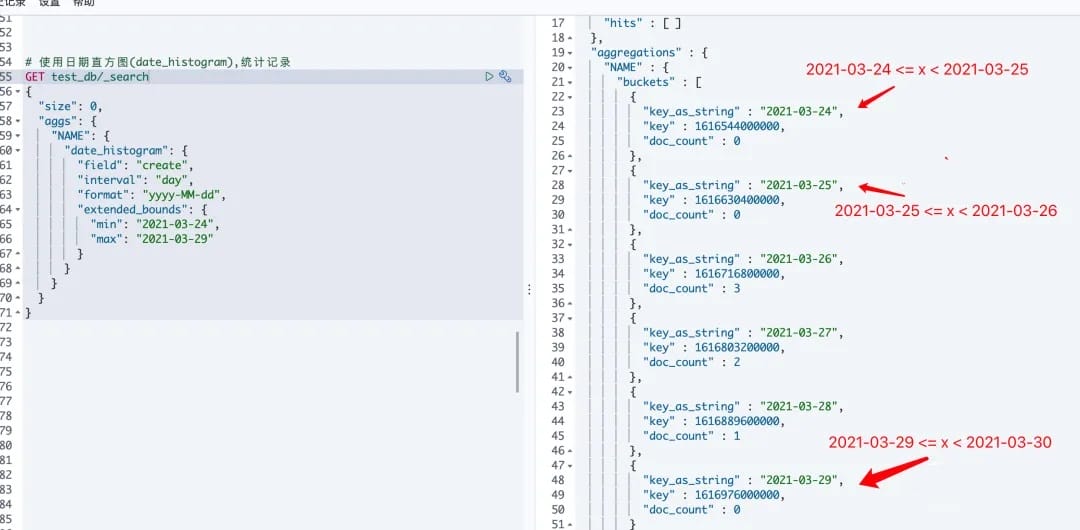
#使用日期直方图(date_histogram),统计记录
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"size": 0,
"aggs": {
"NAME": {
"date_histogram": {
"field": "create",
"interval": "day",
"format": "yyyy-MM-dd",
"extended_bounds": {
"min": "2021-03-24",
"max": "2021-03-29"
}
}
}
}
}'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 4.Metric指标分析
计算最大值,最小值,平均值等,类似 COUNT 、 SUM() 、 MAX() 等统计方法。
# 4.1 单值分析
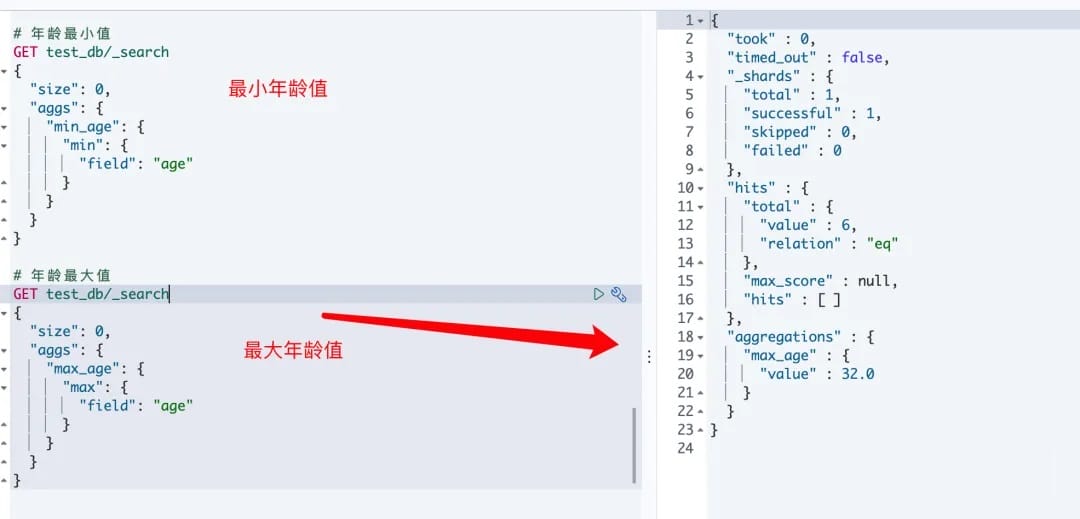
# 1. 最大和最小
max:返回数值类字段的最大值min: 返回数值类字段的最小值
1.语法
{
"size": 0,
"aggs": {
"自定义分组名": {
"max/min": {
"field": "字段"
}
}
}
}
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
2.使用
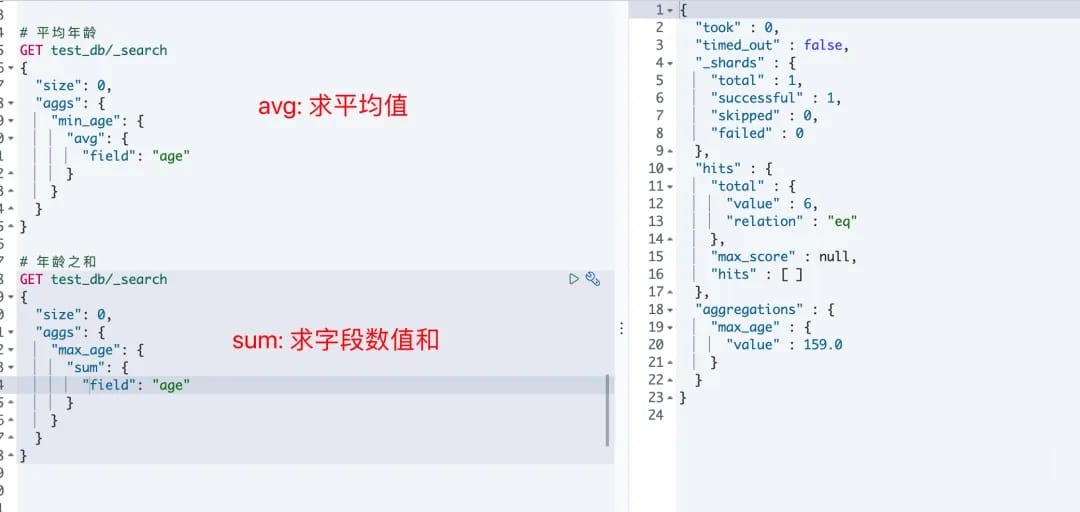
# 2. 平均值、求和
avg: 返回数值类字段的平均值sum:返回数值类字段的总和
1.使用
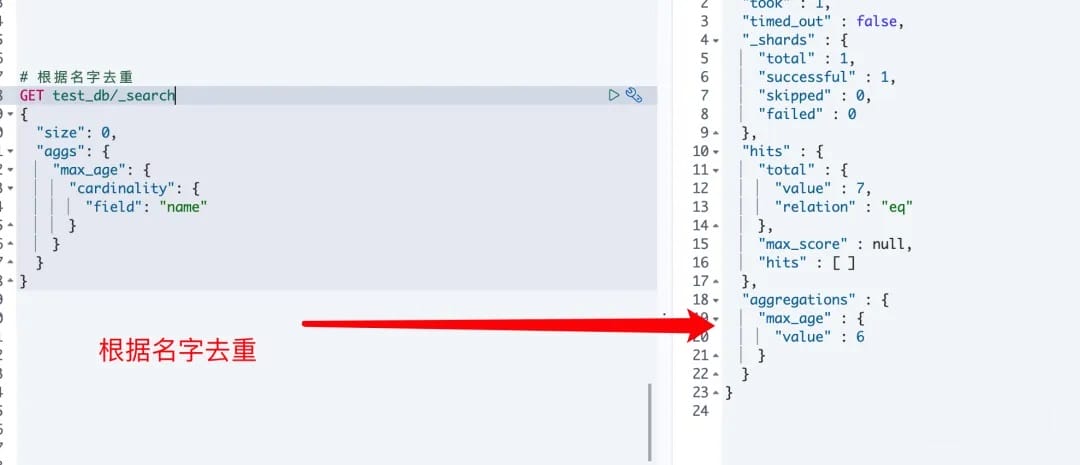
# 3.去重
cardinality: 是指不同数值的个数,类似SQL中的distinct count概念
1.使用
# 4.2 多值分析
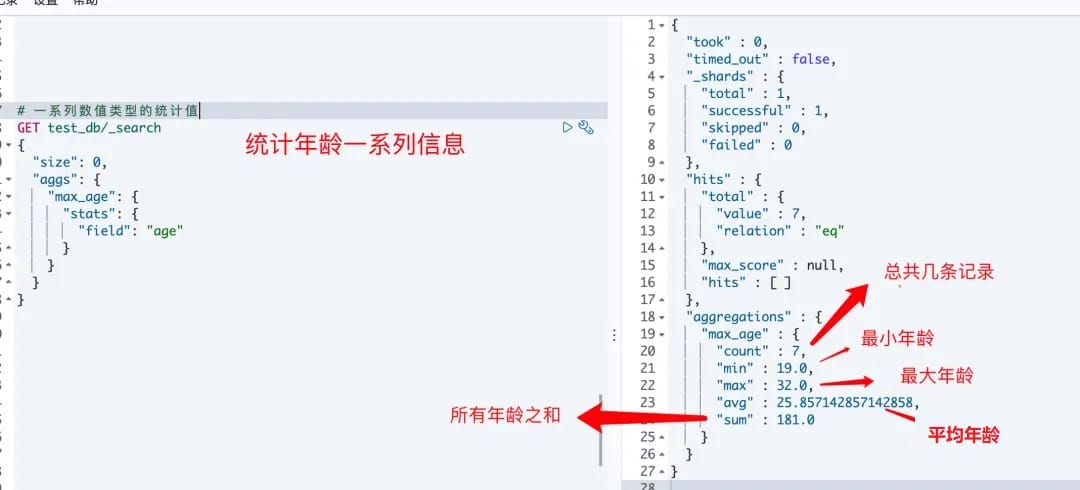
# 1.Stats
返回一系列数值类型的统计值,包含min,max,avg,sum和count,被分析的字段只能是数字类型
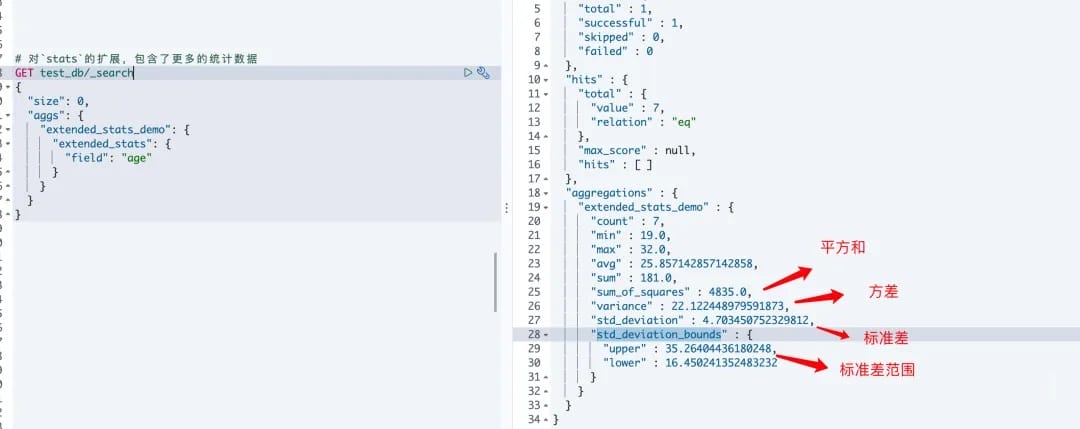
# 2.Extended Stats
对stats的扩展,包含了更多的统计数据,如方差,标准差等
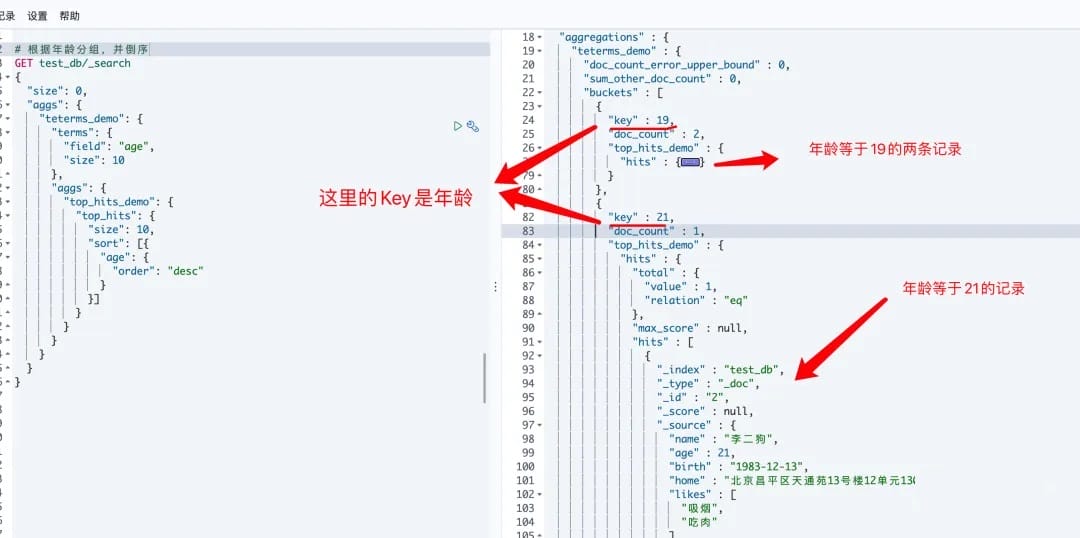
# 3.top_hits
一般用于分桶后获取桶内最匹配的顶部文档列表,即详情数据
# 根据年龄分组,并倒序
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"size":0,
"aggs":{
"teterms_demo":{
"terms":{
"field":"age",
"size":10
},
"aggs":{
"top_hits_demo":{
"top_hits":{
"size":10,
"sort":[
{
"age":{
"order":"desc"
}
}
]
}
}
}
}
}
}'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 5.聚合附加条件
# 5.1 filter
filter: 为聚合分析设定过滤条件。
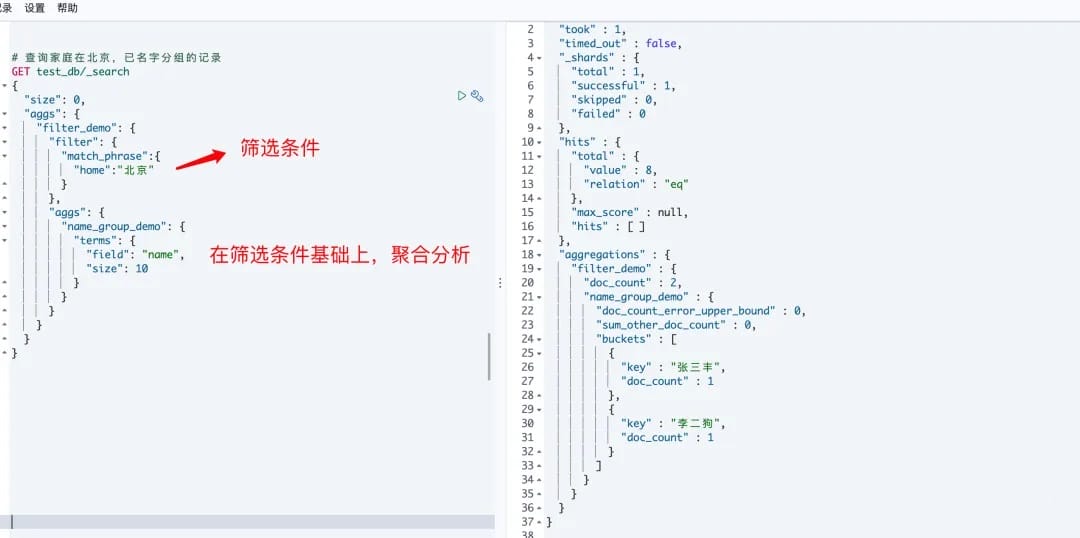
# 查询家庭在北京,已名字分组的记录
curl -XGET "http://elasticsearch:9200/test_db/_search" -H 'Content-Type: application/json' -d'{
"size": 0,
"aggs": {
"filter_demo": {
"filter": {
"match_phrase":{
"home":"北京"
}
},
"aggs": {
"name_group_demo": {
"terms": {
"field": "name",
"size": 10
}
}
}
}
}
}'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
注意这里的数据结构嵌套。
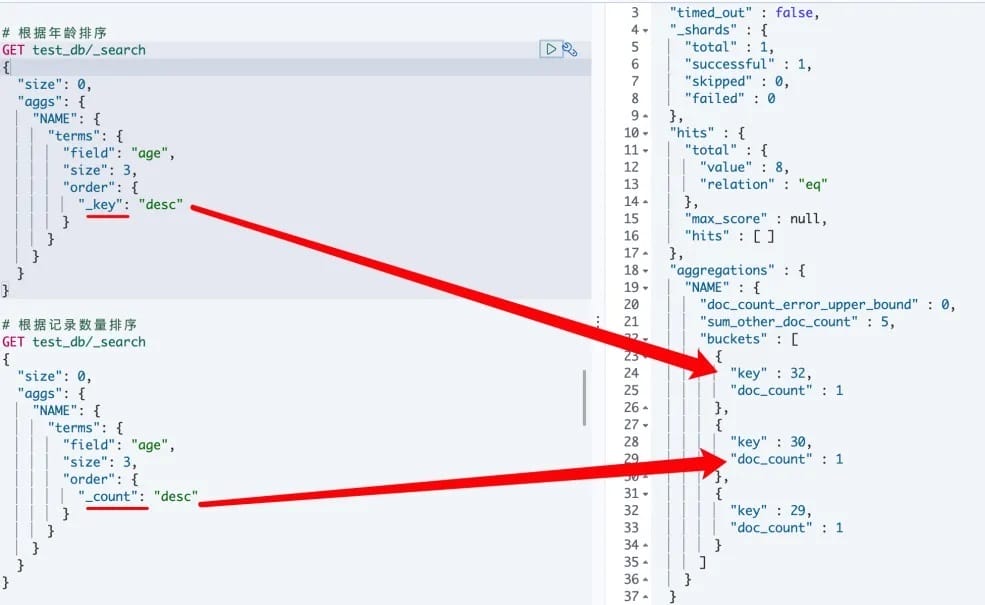
# 6.聚合后排序
可以使用自带的关键数据进行排序,如下:
_count: 文档数_key: 按照key值排序