JUC集合类
- JUC集合: ConcurrentHashMap详解
- JUC集合: CopyOnWriteArrayList详解
- JUC集合: ConcurrentLinkedQueue详解
- JUC集合: BlockingQueue详解
# ConcurrentHashMap
# 1、为什么HashTable慢? 它的并发度是什么? 那么ConcurrentHashMap并发度是什么?
Hashtable之所以效率低下主要是因为其实现使用了synchronized关键字对put等操作进行加锁,而synchronized关键字加锁是对整个对象进行加锁,也就是说在进行put等修改Hash表的操作时,锁住了整个Hash表,从而使得其表现的效率低下。
# 2、ConcurrentHashMap在JDK1.7和JDK1.8中实现有什么差别? JDK1.8解決了JDK1.7中什么问题
HashTable: 使用了synchronized关键字对put等操作进行加锁;ConcurrentHashMap JDK1.7: 使用分段锁机制实现;ConcurrentHashMap JDK1.8: 则使用数组+链表+红黑树数据结构和CAS原子操作实现;
# 3、ConcurrentHashMap JDK1.7实现的原理是什么?
在JDK1.5~1.7版本,Java使用了分段锁机制实现ConcurrentHashMap.
简而言之,ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;而每个Segment元素,它通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作。
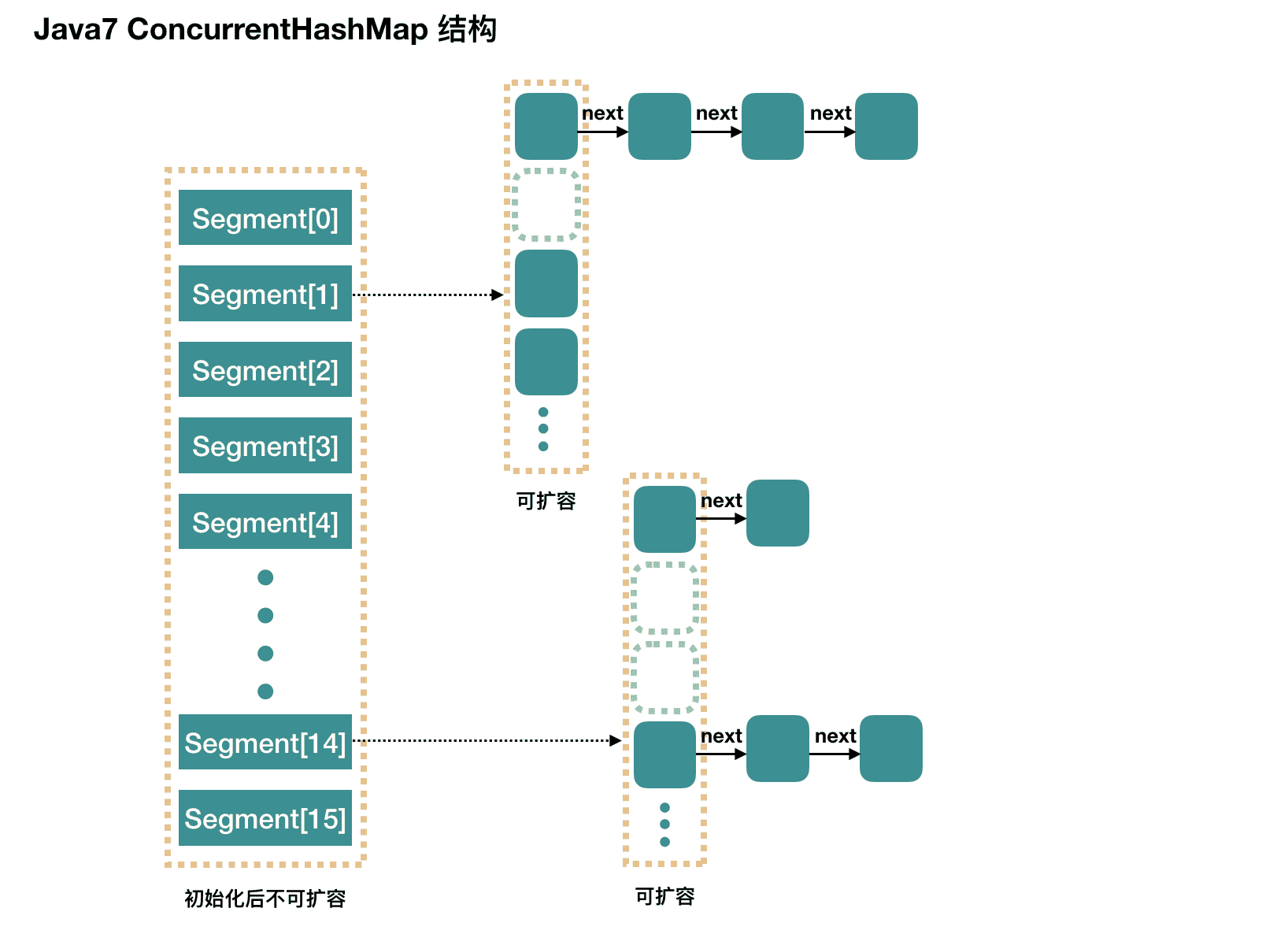
concurrencyLevel: Segment 数(并行级别、并发数)。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
# 4、ConcurrentHashMap JDK1.7中Segment数(concurrencyLevel)默认值是多少? 为何一旦初始化就不可再扩容?
默认是 16
# 5、ConcurrentHashMap JDK1.7说说其put的机制?
整体流程还是比较简单的,由于有独占锁的保护,所以 segment 内部的操作并不复杂
- 计算 key 的 hash 值
- 根据 hash 值找到 Segment 数组中的位置 j; ensureSegment(j) 对 segment[j] 进行初始化(Segment 内部是由 数组+链表 组成的)
- 插入新值到 槽 s 中
# 6、ConcurrentHashMap JDK1.7是如何扩容的?
rehash(注:segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry<K,V>[] 进行扩容)
# 7、ConcurrentHashMap JDK1.8实现的原理是什么?
在JDK1.7之前,ConcurrentHashMap是通过分段锁机制来实现的,所以其最大并发度受Segment的个数限制。因此,在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
简而言之:数组+链表+红黑树,CAS
# 8、ConcurrentHashMap JDK1.8是如何扩容的?
tryPresize, 扩容也是做翻倍扩容的,扩容后数组容量为原来的 2 倍
# 9、ConcurrentHashMap JDK1.8链表转红黑树的时机是什么? 临界值为什么是8?
size = 8, log(N)
# 10、ConcurrentHashMap JDK1.8是如何进行数据迁移的?
transfer, 将原来的 tab 数组的元素迁移到新的 nextTab 数组中
# 11、先说说非并发集合中Fail-fast机制?
快速失败
# CopyOnWriteArrayList
# 1、CopyOnWriteArrayList的实现原理?
COW基于拷贝
// 将toCopyIn转化为Object[]类型数组,然后设置当前数组
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
2
属性中有一个可重入锁,用来保证线程安全访问,还有一个Object类型的数组,用来存放具体的元素。当然,也使用到了反射机制和CAS来保证原子性的修改lock域。
// 可重入锁
final transient ReentrantLock lock = new ReentrantLock();
// 对象数组,用于存放元素
private transient volatile Object[] array;
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// lock域的内存偏移量
private static final long lockOffset;
2
3
4
5
6
7
8
# 2、弱一致性的迭代器原理是怎么样的?
COWIterator
COWIterator表示迭代器,其也有一个Object类型的数组作为CopyOnWriteArrayList数组的快照,这种快照风格的迭代器方法在创建迭代器时使用了对当时数组状态的引用。此数组在迭代器的生存期内不会更改,因此不可能发生冲突,并且迭代器保证不会抛出 ConcurrentModificationException。创建迭代器以后,迭代器就不会反映列表的添加、移除或者更改。在迭代器上进行的元素更改操作(remove、set 和 add)不受支持。这些方法将抛出 UnsupportedOperationException。
# 3、CopyOnWriteArrayList为什么并发安全且性能比Vector好?
Vector对单独的add,remove等方法都是在方法上加了synchronized; 并且如果一个线程A调用size时,另一个线程B 执行了remove,然后size的值就不是最新的,然后线程A调用remove就会越界(这时就需要再加一个Synchronized)。这样就导致有了双重锁,效率大大降低,何必呢。于是vector废弃了,要用就用CopyOnWriteArrayList 吧。
# 4、CopyOnWriteArrayList有何缺陷,说说其应用场景?
CopyOnWriteArrayList 有几个缺点:
- 由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc
- 不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个set操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求;
CopyOnWriteArrayList 合适读多写少的场景,不过这类慎用
因为谁也没法保证CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次add/set都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
# ConcurrentLinkedQueue
# 1、要想用线程安全的队列有哪些选择?
Vector,Collections.synchronizedList( List list), ConcurrentLinkedQueue等
# 2、ConcurrentLinkedQueue实现的数据结构?
ConcurrentLinkedQueue的数据结构与LinkedBlockingQueue的数据结构相同,都是使用的链表结构。ConcurrentLinkedQueue的数据结构如下:

说明: ConcurrentLinkedQueue采用的链表结构,并且包含有一个头节点和一个尾结点。
# 3、ConcurrentLinkedQueue底层原理?
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// head域的偏移量
private static final long headOffset;
// tail域的偏移量
private static final long tailOffset;
2
3
4
5
6
说明: 属性中包含了head域和tail域,表示链表的头节点和尾结点,同时,ConcurrentLinkedQueue也使用了反射机制和CAS机制来更新头节点和尾结点,保证原子性。
# 4、ConcurrentLinkedQueue的核心方法有哪些?
offer(),poll(),peek(),isEmpty()等队列常用方法
# 5、说说ConcurrentLinkedQueue的HOPS(延迟更新的策略)的设计?
通过上面对offer和poll方法的分析,我们发现tail和head是延迟更新的,两者更新触发时机为:
- tail更新触发时机:当tail指向的节点的下一个节点不为null的时候,会执行定位队列真正的队尾节点的操作,找到队尾节点后完成插入之后才会通过casTail进行tail更新;当tail指向的节点的下一个节点为null的时候,只插入节点不更新tail。
- head更新触发时机:当head指向的节点的item域为null的时候,会执行定位队列真正的队头节点的操作,找到队头节点后完成删除之后才会通过updateHead进行head更新;当head指向的节点的item域不为null的时候,只删除节点不更新head。
并且在更新操作时,源码中会有注释为:hop two nodes at a time。所以这种延迟更新的策略就被叫做HOPS的大概原因是这个(猜的 😃),从上面更新时的状态图可以看出,head和tail的更新是“跳着的”即中间总是间隔了一个。那么这样设计的意图是什么呢?
如果让tail永远作为队列的队尾节点,实现的代码量会更少,而且逻辑更易懂。但是,这样做有一个缺点,如果大量的入队操作,每次都要执行CAS进行tail的更新,汇总起来对性能也会是大大的损耗。如果能减少CAS更新的操作,无疑可以大大提升入队的操作效率,所以doug lea大师每间隔1次(tail和队尾节点的距离为1)进行才利用CAS更新tail。对head的更新也是同样的道理,虽然,这样设计会多出在循环中定位队尾节点,但总体来说读的操作效率要远远高于写的性能,因此,多出来的在循环中定位尾节点的操作的性能损耗相对而言是很小的。
# 6、ConcurrentLinkedQueue适合什么样的使用场景?
ConcurrentLinkedQueue通过无锁来做到了更高的并发量,是个高性能的队列,但是使用场景相对不如阻塞队列常见,毕竟取数据也要不停的去循环,不如阻塞的逻辑好设计,但是在并发量特别大的情况下,是个不错的选择,性能上好很多,而且这个队列的设计也是特别费力,尤其的使用的改良算法和对哨兵的处理。整体的思路都是比较严谨的,这个也是使用了无锁造成的,我们自己使用无锁的条件的话,这个队列是个不错的参考。
# BlockingDeque
# 1、什么是BlockingDeque? 适合用在什么样的场景?
BlockingQueue 通常用于一个线程生产对象,而另外一个线程消费这些对象的场景。下图是对这个原理的阐述:

一个线程往里边放,另外一个线程从里边取的一个 BlockingQueue。
一个线程将会持续生产新对象并将其插入到队列之中,直到队列达到它所能容纳的临界点。也就是说,它是有限的。如果该阻塞队列到达了其临界点,负责生产的线程将会在往里边插入新对象时发生阻塞。它会一直处于阻塞之中,直到负责消费的线程从队列中拿走一个对象。 负责消费的线程将会一直从该阻塞队列中拿出对象。如果消费线程尝试去从一个空的队列中提取对象的话,这个消费线程将会处于阻塞之中,直到一个生产线程把一个对象丢进队列。
# 2、BlockingQueue大家族有哪些?
ArrayBlockingQueue, DelayQueue, LinkedBlockingQueue, SynchronousQueue...
# 3、BlockingQueue常用的方法?
BlockingQueue 具有 4 组不同的方法用于插入、移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:
| 抛异常 | 特定值 | 阻塞 | 超时 | |
|---|---|---|---|---|
| 插入 | add(o) | offer(o) | put(o) | offer(o, timeout, timeunit) |
| 移除 | remove() | poll() | take() | poll(timeout, timeunit) |
| 检查 | element() | peek() |
四组不同的行为方式解释:
- 抛异常: 如果试图的操作无法立即执行,抛一个异常。
- 特定值: 如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
- 阻塞: 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
- 超时: 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。
# 4、BlockingQueue 实现例子?
这里是一个 Java 中使用 BlockingQueue 的示例。本示例使用的是 BlockingQueue 接口的 ArrayBlockingQueue 实现。 首先,BlockingQueueExample 类分别在两个独立的线程中启动了一个 Producer 和 一个 Consumer。Producer 向一个共享的 BlockingQueue 中注入字符串,而 Consumer 则会从中把它们拿出来。
public class BlockingQueueExample {
public static void main(String[] args) throws Exception {
BlockingQueue queue = new ArrayBlockingQueue(1024);
Producer producer = new Producer(queue);
Consumer consumer = new Consumer(queue);
new Thread(producer).start();
new Thread(consumer).start();
Thread.sleep(4000);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
以下是 Producer 类。注意它在每次 put() 调用时是如何休眠一秒钟的。这将导致 Consumer 在等待队列中对象的时候发生阻塞。
public class Producer implements Runnable{
protected BlockingQueue queue = null;
public Producer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
try {
queue.put("1");
Thread.sleep(1000);
queue.put("2");
Thread.sleep(1000);
queue.put("3");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
以下是 Consumer 类。它只是把对象从队列中抽取出来,然后将它们打印到 System.out。
public class Consumer implements Runnable{
protected BlockingQueue queue = null;
public Consumer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
try {
System.out.println(queue.take());
System.out.println(queue.take());
System.out.println(queue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# BlockingDeque
# 1、什么是BlockingDeque? 适合用在什么样的场景?
java.util.concurrent 包里的 BlockingDeque 接口表示一个线程安放入和提取实例的双端队列。
BlockingDeque 类是一个双端队列,在不能够插入元素时,它将阻塞住试图插入元素的线程;在不能够抽取元素时,它将阻塞住试图抽取的线程。 deque(双端队列) 是 "Double Ended Queue" 的缩写。因此,双端队列是一个你可以从任意一端插入或者抽取元素的队列。
在线程既是一个队列的生产者又是这个队列的消费者的时候可以使用到 BlockingDeque。如果生产者线程需要在队列的两端都可以插入数据,消费者线程需要在队列的两端都可以移除数据,这个时候也可以使用 BlockingDeque。BlockingDeque 图解:

# 2、BlockingDeque 与BlockingQueue有何关系,请对比下它们的方法?
BlockingDeque 接口继承自 BlockingQueue 接口。这就意味着你可以像使用一个 BlockingQueue 那样使用 BlockingDeque。如果你这么干的话,各种插入方法将会把新元素添加到双端队列的尾端,而移除方法将会把双端队列的首端的元素移除。正如 BlockingQueue 接口的插入和移除方法一样。
以下是 BlockingDeque 对 BlockingQueue 接口的方法的具体内部实现:
| BlockingQueue | BlockingDeque |
|---|---|
| add() | addLast() |
| offer() x 2 | offerLast() x 2 |
| put() | putLast() |
| remove() | removeFirst() |
| poll() x 2 | pollFirst() |
| take() | takeFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
# 3、BlockingDeque大家族有哪些?
LinkedBlockingDeque 是一个双端队列,在它为空的时候,一个试图从中抽取数据的线程将会阻塞,无论该线程是试图从哪一端抽取数据。
# 4、BlockingDeque 实现例子?
既然 BlockingDeque 是一个接口,那么你想要使用它的话就得使用它的众多的实现类的其中一个。java.util.concurrent 包提供了以下 BlockingDeque 接口的实现类: LinkedBlockingDeque。
以下是如何使用 BlockingDeque 方法的一个简短代码示例:
BlockingDeque<String> deque = new LinkedBlockingDeque<String>();
deque.addFirst("1");
deque.addLast("2");
String two = deque.takeLast();
String one = deque.takeFirst();
2
3
4
5
6