全局唯一ID
# 1、全局唯一ID有哪些实现方案?
常见的分布式ID生成方式,大致分类的话可以分为两类:
- 一种是类DB型的,根据设置不同起始值和步长来实现趋势递增,需要考虑服务的容错性和可用性;
- 另一种是类snowflake型,这种就是将64位划分为不同的段,每段代表不同的涵义,基本就是时间戳、机器ID和序列数。这种方案就是需要考虑时钟回拨的问题以及做一些 buffer的缓冲设计提高性能。
# 2、数据库方式实现方案?有什么缺陷?
- MySQL为例
我们将分布式系统中数据库的同一个业务表的自增ID设计成不一样的起始值,然后设置固定的步长,步长的值即为分库的数量或分表的数量。
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增。
auto_increment_offset:表示自增长字段从那个数开始,他的取值范围是1 .. 65535。auto_increment_increment:表示自增长字段每次递增的量,其默认值是1,取值范围是1 .. 65535。
缺点也很明显,首先它强依赖DB,当DB异常时整个系统不可用。虽然配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。还有就是ID发号性能瓶颈限制在单台MySQL的读写性能。
- 使用redis实现
Redis实现分布式唯一ID主要是通过提供像 INCR 和 INCRBY 这样的自增原子命令,由于Redis自身的单线程的特点所以能保证生成的 ID 肯定是唯一有序的。
但是单机存在性能瓶颈,无法满足高并发的业务需求,所以可以采用集群的方式来实现。集群的方式又会涉及到和数据库集群同样的问题,所以也需要设置分段和步长来实现。
为了避免长期自增后数字过大可以通过与当前时间戳组合起来使用,另外为了保证并发和业务多线程的问题可以采用 Redis + Lua的方式进行编码,保证安全。
Redis 实现分布式全局唯一ID,它的性能比较高,生成的数据是有序的,对排序业务有利,但是同样它依赖于redis,需要系统引进redis组件,增加了系统的配置复杂性。
当然现在Redis的使用性很普遍,所以如果其他业务已经引进了Redis集群,则可以资源利用考虑使用Redis来实现。
# 3、雪花算法如何实现的?
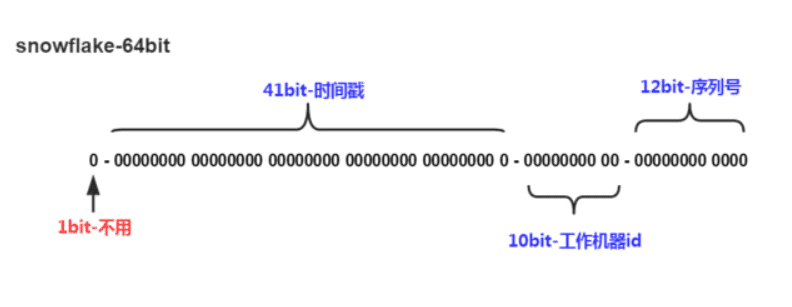
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的。
- 第1位占用1bit,其值始终是0,可看做是符号位不使用。
- 第2位开始的41位是时间戳,41-bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可用的时间年限是
(1L<<41)/(1000L360024*365)=69 年的时间。 - 中间的10-bit位可表示机器数,即2^10 = 1024台机器,但是一般情况下我们不会部署这么台机器。如果我们对IDC(互联网数据中心)有需求,还可以将 10-bit 分 5-bit 给 IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,具体的划分可以根据自身需求定义。
- 最后12-bit位是自增序列,可表示2^12 = 4096个数。
这样的划分之后相当于在一毫秒一个数据中心的一台机器上可产生4096个有序的不重复的ID。但是我们 IDC 和机器数肯定不止一个,所以毫秒内能生成的有序ID数是翻倍的。
# 4、雪花算法有什么问题?有哪些解决思路?
- 有哪些问题?
- 时钟回拨问题;
- 趋势递增,而不是绝对递增;
- 不能在一台服务器上部署多个分布式ID服务;
- 如何解决时钟回拨?
以百度的UidGenerator为例,CachedUidGenerator方式主要通过采取如下一些措施和方案规避了时钟回拨问题和增强唯一性:
- 自增列:UidGenerator的workerId在实例每次重启时初始化,且就是数据库的自增ID,从而完美的实现每个实例获取到的workerId不会有任何冲突。
- RingBuffer:UidGenerator不再在每次取ID时都实时计算分布式ID,而是利用RingBuffer数据结构预先生成若干个分布式ID并保存。
- 时间递增:传统的雪花算法实现都是通过System.currentTimeMillis()来获取时间并与上一次时间进行比较,这样的实现严重依赖服务器的时间。而UidGenerator的时间类型是AtomicLong,且通过incrementAndGet()方法获取下一次的时间,从而脱离了对服务器时间的依赖,也就不会有时钟回拨的问题
(这种做法也有一个小问题,即分布式ID中的时间信息可能并不是这个ID真正产生的时间点,例如:获取的某分布式ID的值为3200169789968523265,它的反解析结果为{"timestamp":"2019-05-02 23:26:39","workerId":"21","sequence":"1"},但是这个ID可能并不是在"2019-05-02 23:26:39"这个时间产生的)。