Kubernetes
# 1、什么是Kubernetes? Kubernetes与Docker有什么关系?
- 是什么?
Kubernetes是一个开源容器管理工具,负责容器部署,容器扩缩容以及负载平衡。作为Google的创意之作,它提供了出色的社区,并与所有云提供商合作。因此,我们可以说Kubernetes不是一个容器化平台,而是一个多容器管理解决方案。
众所周知,Docker提供容器的生命周期管理,Docker镜像构建运行时容器。但是,由于这些单独的容器必须通信,因此使用Kubernetes。因此,我们说Docker构建容器,这些容器通过Kubernetes相互通信。因此,可以使用Kubernetes手动关联和编排在多个主机上运行的容器。
- 有哪些特性?
- 自我修复: 在节点故障时可以删除失效容器,重新创建新的容器,替换和重新部署,保证预期的副本数量,kill掉健康检查失败的容器,并且在容器未准备好之前不会处理客户端情况,确保线上服务不会中断
- 弹性伸缩: 使用命令、UI或者k8s基于cpu使用情况自动快速扩容和缩容应用程序实例,保证应用业务高峰并发时的高可用性,业务低峰时回收资源,以最小成本运行服务
- 自动部署和回滚: k8s采用滚动更新策略更新应用,一次更新一个pod,而不是同时删除所有pod,如果更新过程中出现问题,将回滚恢复,确保升级不影响业务
- 服务发现和负载均衡: k8s为多个容器提供一个统一访问入口(内部IP地址和一个dns名称)并且负载均衡关联的所有容器,使得用户无需考虑容器IP问题
- 机密和配置管理: 管理机密数据和应用程序配置,而不需要把敏感数据暴露在径向力,提高敏感数据安全性,并可以将一些常用的配置存储在k8s中,方便应用程序调用
- 存储编排: 挂载外部存储系统,无论时来自本地存储、公有云(aws)、还是网络存储(nfs、GFS、ceph),都作为集群资源的一部分使用,极大提高存储使用灵活性
- 批处理: 提供一次性任务,定时任务:满足批量数据处理和分析的场景
# 2、Kubernetes的整体架构?
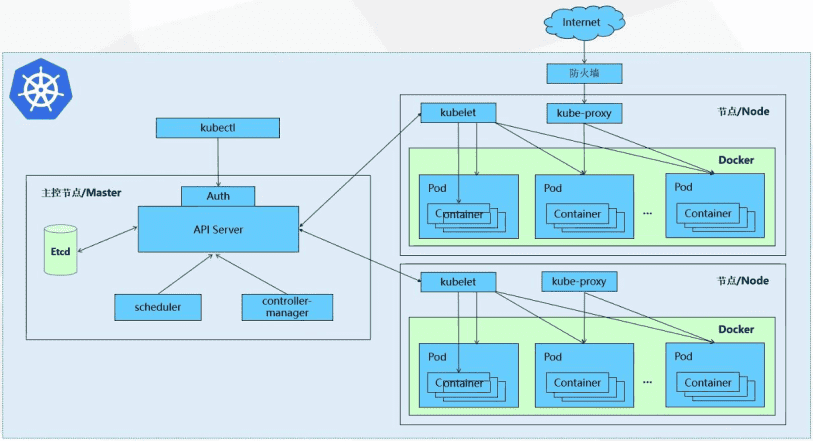
Kubernetes主要由以下几个核心组件组成:
- etcd:提供数据库服务保存了整个集群的状态
- kube-apiserver:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制
- kube-controller-manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
- cloud-controller-manager:是与底层云计算服务商交互的控制器
- kub-scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
- kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
- kube-proxy:负责为Service提供内部的服务发现和负载均衡,并维护网络规则
- container-runtime:是负责管理运行容器的软件,比如docker
除了核心组件,还有一些推荐的Add-ons:
- kube-dns负责为整个集群提供DNS服务
- Ingress Controller为服务提供外网入口
- Heapster提供资源监控
- Dashboard提供GUI
- Federation提供跨可用区的集群
- Fluentd-elasticsearch提供集群日志采集、存储与查询
# 3、Kubernetes中有哪些核心概念?
- Cluster、Master、Node
Cluster
- Cluster(集群) 是计算、存储和网络资源的集合,Kubernetes 利用这些资源运行各种基于容器的应用。最简单的 Cluster 可以只有一台主机(它既是 Mater 也是 Node)
Master
- Master 是 Cluster 的大脑,它的主要职责是调度,即决定将应用放在哪里运行。
- Master 运行 Linux 操作系统,可以是物理机或者虚拟机。
- 为了实现高可用,可以运行多个 Master。
Node
- Node 的职责是运行容器应用。
- Node 由 Master 管理,Node 负责监控并汇报容器的状态,并根据 Master 的要求管理容器的生命周期。
- Node 运行在 Linux 操作系统,可以是物理机或者是虚拟机。
- Pod
基本概念
- Pod 是 Kubernetes 的最小工作单元。
- 每个 Pod 包含一个或多个容器。Pod 中的容器会作为一个整体被 Master 调度到一个 Node 上运行。
引入 Pod 的目的
可管理性: 有些容器天生就是需要紧密联系,一起工作。Pod 提供了比容器更高层次的抽象,将它们封装到一个部署单元中。Kubernetes 以 Pod 为最小单位进行调度、扩展、共享资源、管理生命周期。通信和资源共享: Pod 中的所有容器使用同一个网络 namespace,即相同的 IP 地址和 Port 空间。它们可以直接用 localhost 通信。同样的,这些容器可以共享存储,当 Kubernetes 挂载 volume 到 Pod,本质上是将 volume 挂载到 Pod 中的每一个容器。
Pod 的使用方式
运行单一容器: one-container-per-Pod 是 Kubernetes 最常见的模型,这种情况下,只是将单个容器简单封装成 Pod。即便是只有一个容器,Kubernetes 管理的也是 Pod 而不是直接管理容器。运行多个容器: 对于那些联系非常紧密,而且需要直接共享资源的容器,应该放在一个 Pod 中。比如下面这个 Pod 包含两个容器:一个 File Puller,一个是 Web Server。File Puller 会定期从外部的 Content Manager 中拉取最新的文件,将其存放在共享的 volume 中。Web Server 从 volume 读取文件,响应 Consumer 的请求。这两个容器是紧密协作的,它们一起为 Consumer 提供最新的数据;同时它们也通过 volume 共享数据。所以放到一个 Pod 是合适的。
- Controller
基本概念
- Kubernetes 通常不会直接创建 Pod,而是通过 Controller 来管理 Pod 的。Controller 中定义了 Pod 的部署特性,比如有几个副本,在什么样的 Node 上运行等。为了满足不同的业务场景,Kubernetes 提供了多种 Controller,包括 Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job 等。
各个 Controller
Deployment: Deployment 是最常用的 Controller,比如我们可以通过创建 Deployment 来部署应用的。Deployment 可以管理 Pod 的多个副本,并确保 Pod 按照期望的状态运行。ReplicaSet: ReplicaSet 实现了 Pod 的多副本管理。使用 Deployment 时会自动创建 ReplicaSet,也就是说 Deployment 是通过 ReplicaSet 来管理 Pod 的多个副本,我们通常不需要直接使用 ReplicaSet。DaemonSet: DaemonSet 用于每个 Node 最多只运行一个 Pod 副本的场景。正如其名称所揭示的,DaemonSet 通常用于运行 daemon。StatefuleSet: StatefuleSet 能够保证 Pod 的每个副本在整个生命周期中名称是不变的。而其他 Controller 不提供这个功能,当某个 Pod 发生故障需要删除并重新启动时,Pod 的名称会发生变化。同时 StatefuleSet 会保证副本按照固定的顺序启动、更新或者删除。Job: Job 用于运行结束就删除的应用。而其他 Controller 中的 Pod 通常是长期持续运行。
- Service、Namespace
Service
- Deployment 可以部署多个副本,每个 Pod 都有自己的 IP。而 Pod 很可能会被频繁地销毁和重启,它们的 IP 会发生变化,用 IP 来访问 Deployment 副本不太现实。
- Service 定义了外界访问一组特定 Pod 的方式。Service 有自己的 IP 和端口,Service 为 Pod 提供了负载均衡。
Namespace
- Namespace 可以将一个物理的 Cluster 逻辑上划分成多个虚拟 Cluster,每个 Cluster 就是一个 Namespace。不同 Namespace 里的资源是完全隔离的。
- Kubernetes 默认创建了两个 Namespace:
- default:创建资源时如果不指定,将被放到这个 Namespace 中。
- kube-system:Kubernetes 自己创建的系统资源将放到这个 Namespace 中。
# 4、什么是Heapster?
Heapster是由每个节点上运行的Kubelet提供的集群范围的数据聚合器。此容器管理工具在Kubernetes集群上本机支持,并作为pod运行,就像集群中的任何其他pod一样。因此,它基本上发现集群中的所有节点,并通过机上Kubernetes代理查询集群中Kubernetes节点的使用信息。
# 5、什么是Minikube?
Minikube是一种工具,可以在本地轻松运行Kubernetes。这将在虚拟机中运行单节点Kubernetes群集。
# 6、什么是Kubectl?
Kubectl是一个平台,您可以使用该平台将命令传递给集群。因此,它基本上为CLI提供了针对Kubernetes集群运行命令的方法,以及创建和管理Kubernetes组件的各种方法。
# 7、kube-apiserver和kube-scheduler的作用是什么?
kube -apiserver遵循横向扩展架构,是主节点控制面板的前端。这将公开Kubernetes主节点组件的所有API,并负责在Kubernetes节点和Kubernetes主组件之间建立通信。
kube-scheduler负责工作节点上工作负载的分配和管理。因此,它根据资源需求选择最合适的节点来运行未调度的pod,并跟踪资源利用率。它确保不在已满的节点上调度工作负载。
# 8、请你说一下kubenetes针对pod资源对象的健康监测机制?
K8s中对于pod资源对象的健康状态检测,提供了三类probe(探针)来执行对pod的健康监测:
- livenessProbe探针
可以根据用户自定义规则来判定pod是否健康,如果livenessProbe探针探测到容器不健康,则kubelet会根据其重启策略来决定是否重启,如果一个容器不包含livenessProbe探针,则kubelet会认为容器的livenessProbe探针的返回值永远成功。
- ReadinessProbe探针 同样是可以根据用户自定义规则来判断pod是否健康,如果探测失败,控制器会将此pod从对应service的endpoint列表中移除,从此不再将任何请求调度到此Pod上,直到下次探测成功。
- startupProbe探针 启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被上面两类探针kill掉,这个问题也可以换另一种方式解决,就是定义上面两类探针机制时,初始化时间定义的长一些即可。
# 9、K8s中镜像的下载策略是什么?
可通过命令kubectl explain pod.spec.containers来查看imagePullPolicy这行的解释。
K8s的镜像下载策略有三种:Always、Never、IFNotPresent;
- Always:镜像标签为latest时,总是从指定的仓库中获取镜像;
- Never:禁止从仓库中下载镜像,也就是说只能使用本地镜像;
- IfNotPresent:仅当本地没有对应镜像时,才从目标仓库中下载。
默认的镜像下载策略是:当镜像标签是latest时,默认策略是Always;当镜像标签是自定义时(也就是标签不是latest),那么默认策略是IfNotPresent。
# 10、mage的状态有哪些?
- Running:Pod所需的容器已经被成功调度到某个节点,且已经成功运行,
- Pending:APIserver创建了pod资源对象,并且已经存入etcd中,但它尚未被调度完成或者仍然处于仓库中下载镜像的过程
- Unknown:APIserver无法正常获取到pod对象的状态,通常是其无法与所在工作节点的kubelet通信所致。
# 11、如何控制滚动更新过程?
可以通过下面的命令查看到更新时可以控制的参数:
[root@master yaml]# kubectl explain deploy.spec.strategy.rollingUpdate
- maxSurge :此参数控制滚动更新过程,副本总数超过预期pod数量的上限。可以是百分比,也可以是具体的值。默认为1。 (上述参数的作用就是在更新过程中,值若为3,那么不管三七二一,先运行三个pod,用于替换旧的pod,以此类推)
- maxUnavailable:此参数控制滚动更新过程中,不可用的Pod的数量。 (这个值和上面的值没有任何关系,举个例子:我有十个pod,但是在更新的过程中,我允许这十个pod中最多有三个不可用,那么就将这个参数的值设置为3,在更新的过程中,只要不可用的pod数量小于或等于3,那么更新过程就不会停止)。
# 12、DaemonSet资源对象的特性?
DaemonSet这种资源对象会在每个k8s集群中的节点上运行,并且每个节点只能运行一个pod,这是它和deployment资源对象的最大也是唯一的区别。所以,在其yaml文件中,不支持定义replicas,除此之外,与Deployment、RS等资源对象的写法相同。
它的一般使用场景如下:
- 在去做每个节点的日志收集工作;
- 监控每个节点的的运行状态;
# 13、说说你对Job这种资源对象的了解?
Job与其他服务类容器不同,Job是一种工作类容器(一般用于做一次性任务)。使用常见不多,可以忽略这个问题。
#提高Job执行效率的方法:
spec:
parallelism: 2 #一次运行2个
completions: 8 #最多运行8个
template:
metadata:
2
3
4
5
6
# 14、pod的重启策略是什么?
可以通过命令kubectl explain pod.spec查看pod的重启策略。(restartPolicy字段)
- Always:但凡pod对象终止就重启,此为默认策略。
- OnFailure:仅在pod对象出现错误时才重启
# 15、描述一下pod的生命周期有哪些状态?
- Pending:表示pod已经被同意创建,正在等待kube-scheduler选择合适的节点创建,一般是在准备镜像;
- Running:表示pod中所有的容器已经被创建,并且至少有一个容器正在运行或者是正在启动或者是正在重启;
- Succeeded:表示所有容器已经成功终止,并且不会再启动;
- Failed:表示pod中所有容器都是非0(不正常)状态退出;
- Unknown:表示无法读取Pod状态,通常是kube-controller-manager无法与Pod通信。
# 16、创建一个pod的流程是什么?
1) 客户端提交Pod的配置信息(可以是yaml文件定义好的信息)到kube-apiserver; 2) Apiserver收到指令后,通知给controller-manager创建一个资源对象; 3) Controller-manager通过api-server将pod的配置信息存储到ETCD数据中心中; 4) Kube-scheduler检测到pod信息会开始调度预选,会先过滤掉不符合Pod资源配置要求的节点,然后开始调度调优,主要是挑选出更适合运行pod的节点,然后将pod的资源配置单发送到node节点上的kubelet组件上。 5) Kubelet根据scheduler发来的资源配置单运行pod,运行成功后,将pod的运行信息返回给scheduler,scheduler将返回的pod运行状况的信息存储到etcd数据中心。
# 17、删除一个Pod会发生什么事情?
Kube-apiserver会接受到用户的删除指令,默认有30秒时间等待优雅退出,超过30秒会被标记为死亡状态,此时Pod的状态Terminating,kubelet看到pod标记为Terminating就开始了关闭Pod的工作;
关闭流程如下:
- pod从service的endpoint列表中被移除;
- 如果该pod定义了一个停止前的钩子,其会在pod内部被调用,停止钩子一般定义了如何优雅的结束进程;
- 进程被发送TERM信号(kill -14)
- 当超过优雅退出的时间后,Pod中的所有进程都会被发送SIGKILL信号(kill -9)。
# 18、K8s的Service是什么?
Pod每次重启或者重新部署,其IP地址都会产生变化,这使得pod间通信和pod与外部通信变得困难,这时候,就需要Service为pod提供一个固定的入口。
Service的Endpoint列表通常绑定了一组相同配置的pod,通过负载均衡的方式把外界请求分配到多个pod上
# 19、k8s是怎么进行服务注册的?
Pod启动后会加载当前环境所有Service信息,以便不同Pod根据Service名进行通信。
# 20、k8s集群外流量怎么访问Pod?
可以通过Service的NodePort方式访问,会在所有节点监听同一个端口,比如:30000,访问节点的流量会被重定向到对应的Service上面。
# 21、k8s数据持久化的方式有哪些?
- EmptyDir(空目录):
没有指定要挂载宿主机上的某个目录,直接由Pod内保部映射到宿主机上。类似于docker中的manager volume。
主要使用场景:
- 只需要临时将数据保存在磁盘上,比如在合并/排序算法中;
- 作为两个容器的共享存储,使得第一个内容管理的容器可以将生成的数据存入其中,同时由同一个webserver容器对外提供这些页面。
emptyDir的特性: 同个pod里面的不同容器,共享同一个持久化目录,当pod节点删除时,volume的数据也会被删除。如果仅仅是容器被销毁,pod还在,则不会影响volume中的数据。 总结来说:emptyDir的数据持久化的生命周期和使用的pod一致。一般是作为临时存储使用。
- Hostpath:
将宿主机上已存在的目录或文件挂载到容器内部。类似于docker中的bind mount挂载方式。
这种数据持久化方式,运用场景不多,因为它增加了pod与节点之间的耦合。
一般对于k8s集群本身的数据持久化和docker本身的数据持久化会使用这种方式,可以自行参考apiService的yaml文件,位于:/etc/kubernetes/main…目录下。
- PersistentVolume(简称PV):
基于NFS服务的PV,也可以基于GFS的PV。它的作用是统一数据持久化目录,方便管理。
在一个PV的yaml文件中,可以对其配置PV的大小,
指定PV的访问模式:
- ReadWriteOnce:只能以读写的方式挂载到单个节点;
- ReadOnlyMany:能以只读的方式挂载到多个节点;
- ReadWriteMany:能以读写的方式挂载到多个节点。,
以及指定pv的回收策略(这里的回收策略指的是在PV被删除后,在这个PV下所存储的源文件是否删除):
- recycle:清除PV的数据,然后自动回收;
- Retain:需要手动回收;
- delete:删除云存储资源,云存储专用;
若需使用PV,那么还有一个重要的概念:PVC,PVC是向PV申请应用所需的容量大小,K8s集群中可能会有多个PV,PVC和PV若要关联,其定义的访问模式必须一致。定义的storageClassName也必须一致,若群集中存在相同的(名字、访问模式都一致)两个PV,那么PVC会选择向它所需容量接近的PV去申请,或者随机申请。
# 22、Replica Set 和 Replication Controller 之间有什么区别?
Replica Set 和 Replication Controller 几乎完全相同。它们都确保在任何给定时间运行指定数量的 Pod 副本。不同之处在于复制 Pod 使用的选择器。Replica Set 使用基于集合的选择器,而 Replication Controller 使用基于权限的选择器。
Equity-Based 选择器:这种类型的选择器允许按标签键和值进行过滤。因此,在外行术语中,基于 Equity 的选择器将仅查找与标签具有完全相同短语的 Pod。示例:假设您的标签键表示 app = nginx,那么使用此选择器,您只能查找标签应用程序等于 nginx 的那些 Pod。
Selector-Based 选择器:此类型的选择器允许根据一组值过滤键。因此,换句话说,基于 Selector 的选择器将查找已在集合中提及其标签的 Pod。示例:假设您的标签键在(nginx、NPS、Apache)中显示应用程序。然后,使用此选择器,如果您的应用程序等于任何 nginx、NPS或 Apache,则选择器将其视为真实结果。
# 23、其它
基础篇 基础篇主要面向的初级、中级开发工程师职位,主要考察对k8s本身的理解。
kubernetes包含几个组件。各个组件的功能是什么。组件之间是如何交互的。 k8s的pause容器有什么用。是否可以去掉。 k8s中的pod内几个容器之间的关系是什么。 一个经典pod的完整生命周期。 k8s的service和ep是如何关联和相互影响的。 详述kube-proxy原理,一个请求是如何经过层层转发落到某个pod上的整个过程。请求可能来自pod也可能来自外部。 rc/rs功能是怎么实现的。详述从API接收到一个创建rc/rs的请求,到最终在节点上创建pod的全过程,尽可能详细。另外,当一个pod失效时,kubernetes是如何发现并重启另一个pod的? deployment/rs有什么区别。其使用方式、使用条件和原理是什么。 cgroup中的cpu有哪几种限制方式。k8s是如何使用实现request和limit的。
拓展实践篇 拓展实践篇主要面向的高级开发工程师、架构师职位,主要考察实践经验和技术视野。
设想一个一千台物理机,上万规模的容器的kubernetes集群,请详述使用kubernetes时需要注意哪些问题?应该怎样解决?(提示可以从高可用,高性能等方向,覆盖到从镜像中心到kubernetes各个组件等) 设想kubernetes集群管理从一千台节点到五千台节点,可能会遇到什么样的瓶颈。应该如何解决。 kubernetes的运营中有哪些注意的要点。 集群发生雪崩的条件,以及预防手段。 设计一种可以替代kube-proxy的实现 sidecar的设计模式如何在k8s中进行应用。有什么意义。 灰度发布是什么。如何使用k8s现有的资源实现灰度发布。 介绍k8s实践中踩过的比较大的一个坑和解决方式。